Intermediary Architecture
Interposing middleware services and ilities between web client and server
Craig Thompson,
Paul Pazandak, Venu
Vasudevan, Frank Manola,
Mark Palmer, Gil
Hansen, Steve Ford
contact: thompson@objs.com
Object Services and Consulting,
Inc.
November 21, 1997
Abstract
This position paper describes what we are calling
an Intermediary Architecture (IA), a specific infrastructure
architecture for combining web and ORB/service architectures. The
idea is to interpose intermediary middleware plug-in services between the
web client and server. The architecture consists of a generic URL
request interceptor and one or more plug-in services. Services
can be dynamically installed and placed on the client, server, or in between
for different purposes. Services may share
a common service support infrastructure: a system management policy
governs the behavior of a service; services typically store their metadata
in a local or remote, possibly shared repositories; and traders
can be used to discover and federate repositories. In our implementation
(in progress), intermediaries are implemented as light weight proxies;
services can be put in place with minimal changes to existing web infrastructure;
they can be implemented in Java, C++, or other languages or using distributed
programming architectures such as CORBA, DCOM, or ActiveX; and they may
optionally modify the client browser or editor. We
describe examples that use the IA: an annotation service, a personal
web performance monitoring service, and ideas for others. The Intermediary
Architecture appears to be a generally useful way to integrate web architectures
with middleware services. Remaining challenges include composition
of services, scaling, and federation of the IA infrastructure.
Background
The overall thesis of our DARPA project Scaling
Object Services Architectures to the Internet (also see Scaling
OSAs architectural presentation) is that the web and object technology
bases need to be better integrated to realize the benefits of both. We
are working on several aspects of the problem including how to extend OMG's
Object Management Architecture to accommodate architectural properties
like composability, scaling, and evolution (OMA-NG),
what a web object model might look like (Web Object
Model), and new infrastructures for web object middleware integration
(the subject of this paper). In a related DARPA project we are working
on Survivability of Object Services Architectures.
We are long-time active members of OMG, currently chairing its Internet
SIG, relatively recent members of W3C, and active as architects or
reviewers in several other projects including National
Industrial Information Infrastructure Protocols Consortium (NIIIP),
MCC Object Infrastructure Project
(OIP), and DARPA
Advanced Information Technology Services (AITS).
Motivation
Today the Web consists of thin clients, which provide
universal browser interfaces, and web servers, which provide back-end access
to global information resources (e.g., that's where the data is).
Meanwhile ORBs provide access to suites of middleware services (e.g., that's
where the management is). At present, ORBs are not really connected
well to control access to web data sources. Without better integration,
the web community will build protocol extensions (e.g., WEBDAV) parallel
to but different than the ORB community, and enterprise architects will
be forced to make idiosyncratic tradeoffs in constructing systems that
need to use both architectures together.
Web clients and servers today leave certain hooks
for extensibility:
-
client-side browser plug-in APIs - typically these
are selected via the MIME type of the resource being downloaded and support
object viewing
-
client-side composer plug-in APIs - these support
data editing
-
server side plug-in APIs
-
arbitrary CGI operations that return pages and which
may have side-effects like page counts
-
applets embedded within pages to be interpreted by
the client, servlets embedded within pages to be interpreted by the server,
and client-side and server-side scripts embedded in the page
It would be desirable if it were easy for end-users
and developers to plug in modules from component software libraries to
extend web architectures. Middleware ORB-based service architectures
provide candidate component libraries. So a next questions is, how
can we combine web and ORB architectures. Two approaches to web-ORB
integration are already in common use:
-
backend ORBs - server-side CGI scripts call ORB clients
that access middleware services
-
downloading ORB clients as applets - when a Java
applet is downloaded, it contains a Java ORB client that then can communicate
to an ORB server. Netscape's Visigenic CORBA client is pre-downloaded to
optimize the download time.
A third web-ORB integration architecture, which we
are calling an Intermediary Architecture, also appears to be broadly useful
in that it interposes intermediary middleware services directly between
web client request and web server response. There are others as well:
WAI
enables one to associate a (CORBA) service with a URL.
From a somewhat higher vantage point, we (like
others before us) are noticing that Web and ORB architectures are naturally
growing into each other's turf. We are going through an architectural
exercise in comparing the two architectures and then performing an operation
on architectures by extending one with capabilities of the other by splicing
OMG ORB-like service architectures between web client and server, in effect
creating URL brokers.
Intermediary Architecture Examples
The design pattern of interposing intermediary behavior
between components is not new. Wrappers do this in an ad hoc way.
More generally, reflective architectures (e.g., CLOS) provide expansion
joints where new behaviors can be interposed. The DARPA Open OODB
system [Wells, Blakeley, Thompson. "Architecture of an Open Object-Oriented
Database Management System." IEEE Computer, October 1992]
used sentries to install new behaviors like persistence and versioning
and treated querying as a service. OMG's security
architecture uses (nearly) general purpose interceptors to overload
the CORBA dispatch mechanism and install security into OMG's distributed
object architecture. The OMG Portable Object Adapter specification
provides before-after filters. Several groups (ours, MCC OIP, others) are
exploring a general intermediary design pattern for installing QoS -ilities
in communication paths in ORB and now web architectures.
On the web, most work has focused on single-purpose,
hard-wired intermediaries, called proxy servers. A number of http
servers can act as proxy servers to receive a URL from a client and pass
it on to a server, first performing some intermediary operation,
then returning a page through the proxy to the client, possibly side-effecting
the page transfer. Common uses for proxies have been page caching
mechanisms and security firewalls. Web platform vendors are increasingly
bundling functionality that could have been added by intermediaries, so
thin clients are getting fatter:
-
client-side caching - a management interface allows
some control over cache size and can allow the cache to be cleared
-
history mechanism - keeps a record of URLs visited
recently; has a management interface.
-
bookmarks mechanism - keeps a record of URLs
visited recently; has a management interface.
-
multiple views - for instance, the Page Source view
that shows/edits the page in html txt mode and the Page Info view that
provides some metadata about the page and URLs it references
-
SSL-based security
-
optional versioning on the server
-
internationalization support
Some of these also require client-side access to
browser or editor/composer - a lesson we've learned is that the APIs to
these components are deficient in some popular web products. Few have explored
general-purpose, open intermediary architectures: Server-side
includes support feature insertion -- pages are scanned before being
sent to the client for embedded instructions (html tokens) which can direct
further execution. Sun's JavaServer
Toolkit and The Open Group's WAIBA
are closest to our own. The W3C Protocol
Extension Protocol (PEP) is addressing the same need (see more below).
NS Enterprise Server's NSAPI
enables one to attach code to steps in the request-response cycle
In order to better understand the design space
for an intermediary architecture, we prototyped some plug-in services and
the IA support infrastructure and at present are integrating the services
into the infrastructure. The plug-ins we have built include:
-
Annotations
Service. The annotation service
allows a third party (which may be the document author or someone else)
to author annotations to a document. The basic architecture of the
annotation service involves annotation creation and storage in an annotation
metadata repository, and later a URL access which has the side-effect of
accessing annotations from the repository, merging annotations with the
document being returned, and annotation viewing. The annotation service
can be a personal service if the annotation creator and viewer are the
same client. Then the repository may typically be located on the
client. (The repository could equally be provided as a generic service
and still keep separate the personal annotations of different clients.)
The service can be a group service if the service is located at an intermediary
proxy shared by a group and the annotations are shared by the group.
It can be a public annotation service if the annotations are public and
the access knows where to locate them either by being told explicitly or
by some registry/trader that associates annotations
with URLs.
-
Personal
Web Performance Monitor Service. This
service captures network performance metadata including trend data based
on URL accesses. A URL interceptor overloads the access with a data
collection facility that captures route and timing and stores it in a performance
metadata repository. The repository can be federated with other personal
weather repositories to provide performance data for a group. This service's
structure shows off the idea of service augmentors -- several different
network monitor tools can (eventually) be plugged into the framework to
collect different sorts of performance metadata.
-
Query
Service Augmentors. A query service refines a user's query using
query augmentors that improve the performance or accuracy of search results.
Augmentors can use repository information that captures a user's search
preferences and habits. This is currently implemented with CGI access to
an ORB which accesses a search engine and thesaurus, not via the IA, but
it raises an issue of how to more seamlessly connect IA ORBs, CGI accessible
ORBs and downloaded-client ORBs.
-
Additionally, as part of the IA infrastructure prototype,
we are working on a collaborative authoring environment using a versioning
service and stubbed security and compression service pairs.
Others have developed what appear to be candidate
IA services usually for dedicated purposes and minus a compositional service
infrastructure. Some potential examples of services include:
-
shielded pages -- access is blocked for certain users
to a certain pages for certain purposes. Pages can be rated with a level
of security and compared with the user's security clearance. Alternatively,
in rating services, labels are assigned by content providers or by third
party rating services and the client "signs up" with a rating service.
It's worth noting that this is exactly what W3C PICS is proposing to do,
and PICS will be supported by the major browser vendors. What we're effectively
proposing is to extend the general PICS idea to support arbitrary addlet
behavior, as opposed to the built-in behavior specified by PICS (access
the page's rating, possibly by accessing a separate rating service, compare
the rating with what the user has specified the rating should be, and either
allow or disallow access). This also emphasizes the role of an appropriate
object model for representing the required metadata; a suitably generic
model allows customized rating systems to be both defined by rating services
and used by browsers, as opposed to the use of built-in rating systems
that are hard to change.
-
rerouting -- access to a given page is rerouted to
another page. This might be done because the page has been moved.
Or to a mirror site because the target server is overloaded.
-
filtering -- e.g., an AI military doctrine filter
that checks commands for doctrine compliance
-
augmenting or modifying -- e.g., removing, replacing,
adding, customizing advertisements for web pages. Also, locating similar
pages in background mode.
-
logging and system management instrumentation, managing
-- e.g., clocking or charging service, micropayments
-
disconnected, intermittent access to roving web clients
- see Caubweb which
supports intermittent web access via caching specified parts of the web
for access/update during "low-bandwidth periods"
-
tracking URL usage patterns of a community of interest
so you can keep trails for others (application to situation awareness)
-
background indexing of pages you have seen before
so you can find them again (suggested by Murray Mazer)
-
virtual private networks - these are usually handled
at a lower level of the protocol stack but might be handled here
-
indexing of streams of audio or video - other DARPA/ICV
projects do this
-
translingual translation service that translates
pages; closed caption in multiple languages
-
augmenting a web page with voice access to URLs
-
the list is not at all exhaustive!
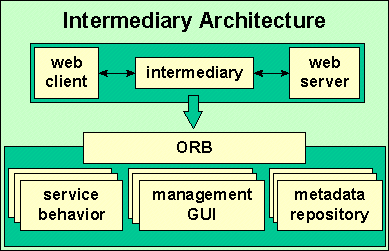
Intermediary Architecture Design Overview
A longer paper documenting our detailed design and
interfaces is in preparation and should be available 1Q98 on our
web site document log.
The idea of the Intermediary Architecture is conceptually
to interpose intermediary middleware plug-in services between the web client
and web server. The main components of the architecture are:
-
URL interceptor. The purpose of the
URL interceptor is to trap and allow for one or many side-effects at the
point before or after of client send, server receive, server send, client
receive.
-
Composition specifications. The
purpose of composition specifications is to sequence a collection of services
so they are executed in a known order. This is the least well understood
component of ours and anyone's similar architecture.
-
Service Plug-in API. This API provides
a means of registering and invoking services at run time including the
ability to add-remove or turn on-off services. Services can be dynamically
installed and placed on the client, server, or in between for different
purposes. Services can be implemented in Java or C++ or using
distributed programming architectures such as CORBA, DCOM, or ActiveX.
-
Services. Services implement some behavior
that a third party can specify. A service itself can be extensible.
Services not only implement side-effect behaviors but may optionally modify
the client browser or editor.
-
Service Support Infrastructure.
Services may or may not share a common service support infrastructure.
-
a system management policy governs their behavior.
Guards are needed to avoid backdoor access problems and enforce policies.
-
services typically store their metadata in a (local
or remote, possibly shared) repository
-
traders can be used to discover and federate repositories
for scaling.
-
security infrastructure is needed to allow trusted
third parties to install and maintain support services.
-
a management GUI is needed to toggle service policies
and parameters
-
some intermediary functions benefit from ready access
to parsed HTML or XML (e.g., adding in-line annotations).
All these could be provided in service specific ways
but they can also be provided in such a way that services can share the
common infrastructure.
ORBs permit the request and response of an object
invocation to be intercepted and manipulated on either the client or the
server side. But commercial web clients (like Netscape Navigator) and servers
so far do not directly support client side or server side filtering.
The experimental Jigsaw server does support server-side filters.
The normal architecture of the web is for a client to issue a GET request
referencing a URL and a server to return the associated resource (page).
Intermediaries provide a general way to augment or overload this access
behavior to add new behaviors. One can draw a wrapper-like picture
of client-IA-server where client is red and server is green and IA has
a green-red layer so the client sees IA as a server and the server sees
IA as a client. This is like mating male and female leads.
One of our design goals was to avoid making changes
to existing web infrastructure and still install the IA architecture.
We closely examined the Netscape browser client API to locate a hook for
URL interceptors but found the API to be pretty minimal and the available
hooks to be insufficient. So in our current prototype (in progress),
intermediaries are implemented as proxies. At first we avoided this
solution because proxy servers are generally heavy weight, but a very thin
pass-through proxy can server as a URL interceptor. This allows IA to be
portable across existing web infrastructure. Commercial browsers
and servers might in the future incorporate IA capabilities or implement
extensible protocols like PEP (see below) to allow IA openness supported
directly in clients or servers. But it appears that both might effectively
just be incorporating (bundling) IA, and there will still be a need for
intermediary implementations separate from client and server as well
as a need for improved client and server APIs.
Intermediaries can be placed on the client, on
the server, or in between. It makes sense to place intermediaries
on the
-
client if the intermediary (optionally) serves the
individual client
-
server if the intermediary serves all clients that
need to access the requested resource(s)
-
in between if the intermediary serves a community
The above placement considerations are not the only
ones. You may want the service on the server-side if the operation needs
to be protected (e.g., it's proprietary and the owner wants to charge for
its use, even if the operation is tailored for a specific client, e.g.,
by a client profile on the server). Also, you may want to locate services
on client or server based on performance tradeoffs (reduce data shipped
over the network by processing at the server, or offload processing from
the server by moving the responsibility to the client), or security considerations.
Brief Comparison of IA with PEP
W3C's Protocol
Extension Protocol (PEP) appears to share the same motivation as IA.
PEP requires web servers to change to install the PEP protocol seamlessly
where IA can make use of existing browsers but requires clients to explicitly
redirect their browser to an IA proxy - really this is a small difference,
we use proxies as a way to intercept URLs and if PEP-enabled servers provided
this, we could use PEP. Both PEP and IA provide for sequencing of intermediate
side-effecting services and dynamic loading of new services. At this level,
both assume services that are protocol independent. PEP reasonably stops
short of suggesting much about an infrastructure for services (policies,
federated repositories, traders) nor is it exploring ORB services as plug
ins or client-side extension mechanisms.
Next Steps
Our next steps are:
-
revise our current prototypes to fit into the emerging
IA architecture.
-
demonstrate IA accessing ORB services.
-
gain experience with the IA architecture style.
-
implement additional services to settle on a plug-in
API that is rich enough for use by third parties and generic enough so
it is not service-specific.
-
implement enough services to understand more about
common IA infrastructure support services and build them as components.
Most interesting to us:
-
learn how to distribute these services and how to
scale the infrastructure architecture via decentralized, federated services
like repositories, traders, policy managers,
and negotiators.
-
learn how to use IA services to make web servers
QoS (generally -ility) aware by inserting new side-effect behaviors (security,
monitors, ...) into communication paths.
-
demonstrate IA and its services in a DoD application,
to be selected.
-
continue to work with OMG and W3C to transfer what
we learn on this project into wide-spread use.
Conclusion
Work on component-based architectures is in its infancy.
The IA presented here appears to be a productive architecture pattern though
there is still much to learn before we can confirm this. It appears to
offer a convenient way to deliver new services to end users in a way that
may be amenable to visual application assembly from a potential smorgasbord
of standard services that could be made available by third parties, opening
the door a little wider for a component economy. The idea is not entirely
new, so we can learn from related work on ORB interceptors and MOPs.
There remain several unexplored questions about
IA architectures:
-
Some uses of intermediaries might bring up legal
issues like copyright (see the Xanadu notion of transclusion)
since web pages originally authored and copyrighted by one party might
appear changed by some third party without the author's permission. This
is reasonable in some circumstances, not in others.
-
We have not yet considered safety issues. Who can
install new services in a users path? IA seems to offer some nice opportunities
for separation of roles via third party experts - allowing a security function
to install security, a configuration board to manage versioning and deployment,
a system management function to monitor bandwidth, and services subscribed
to to push, filter, or block information.
-
The boundaries of the IA are not yet clear.
Should the IA include access to web browser/editor client and server APIs?
Should the service support infrastructure be kept separate from the
interceptor and service sequencing?
-
We don't know all there is to know about composition
of services (nor does OMG!). We have explored sequencing services
in series but can see parallel, compositional, or scripted composition
as useful too. In some cases, proxies occur in pairs (e.g., compress-decompress,
encode-decode) which means there may be higher level controls.
-
We are not sure yet how to generalize IA with other
Web-ORB integration architectures, HTTP-NG, and CORBA/IIOP so that all
these architectures will tend toward convergence. For instance, it
would be most useful if IA services could plug into ORBs and vice versa;
also some IA services might just as well be intermediaries between servers
than client and server. It would seem these might all generalize
to end up as one architecture. But not unless the community can demonstrate
a path to convergence. The alternative is industry spending many $B on
replicating similar functionality in similar but different infrastructure
environments.
-
A related problem is the kind of object
model that is appropriate for both web and ORB, which we assume will
be based on industry developments (XML, Document Object Model) that converge
Web and object representations with APIs (IDL, Java) and object services.
If we are successful in providing a widely useful
architecture for web plus object integration, we will help to provide "objects
for the masses" in the form of an understandable abstract framework for
scaling, composing, and federating services to enable rapid application
development.
Related OBJS papers include OMA-NG,
Survivability, Web
Object Model, Trader, Annotations
Service, Performance
Monitor Service, and Query
Augmentor Service, and others.
This research is sponsored by the Defense Advanced Research
Projects Agency and managed by the U.S. Army Research Laboratory under
contract DAAL01-95-C-0112. The views and conclusions contained in this
document are those of the authors and should not be interpreted as necessarily
representing the official policies, either expressed or implied of the
Defense Advanced Research Projects Agency, U.S. Army Research Laboratory,
or the United States Government.
© Copyright 1997 Object Services and Consulting,
Inc. Permission is granted to copy this document provided this copyright
statement is retained in all copies. Disclaimer: OBJS does not warrant
the accuracy or completeness of the information in this paper.
Last revised: December 8, 1997. Send comments to
Craig Thompson.