WebTrader: Agent Discovery
Project Summary
Tom Bannon and
Craig
Thompson
Object Services and Consulting, Inc.
17 June 2002
Contents
Executive Summary
WebTrader is a lightweight trader/matchmaker/yellow pages that is scalable
to WAN environments and can be used to locate Internet resources (e.g.,
services, agents, data sources, search engines, other traders, anything)
whose advertisements can appear on any web page, represented in XML.
WebTrader depends on existing search engines to index the advertisements
and effectively provides a meta search front end that can locate Web pages
containing advertisements that match its query.
We demonstrated evolving versions of WebTrader at CoABS Workshops at
Las Vegas (January 1999), Northhampton (June 1999), Science Fair in Arlington
(October 1999), Atlanta (February 2000), and Boston (August 2000).
Thereafter, we halted the project, per Jim Hendler's guidance, to provide
added resources for eGents and MIATA, CoAX and JBI TIEs.


Objective
The objective of the WebTrader project is to develop
WebTrader
Query Tool (aka WebTrader), a trader/matchmaker/yellow pages that can
scale to WANs and permit anyone on the Web to advertise a resource (e.g.,
agent, service, data source, search engines) that anyone else can discover.
The approach to scaling is to represent advertisements in XML, store them
on Web pages, let existing already pervasive and industrial strength search
engines index these pages, then WebTrader's engine accesses one or more
search engines, locates pages with advertisements, matches the ads against
the request, and returns the matching advertisements. One interesting
application of WebTrader Query Tool is DeepSearch, a recursive/federated
implementation of WebTrader that acts like a normal search engine but locates
search engines at local sites and recursively searches these. Many
web search engines only index top-level pages leaving the other half of
the web unindexed except by these local search engines.
Specific scientific and engineering subgoals were:
-
represent Internet resource advertisements for services,
agents, data sources, search engines, traders. (This opens the door
to the ontology problem that is the focus of the DARPA DAML program.)
-
locate these advertisements via WebTrader which itself
piggybacks on one or more Internet search engines that have indexed the
resource advertisements
-
demonstrate trader federation and rebinding
-
re-engineer client-server WebTrader so the client
is an applet that can download quickly to most browsers
-
explore how to locate and mine local domain search
engines as a way to broaden and deepen Web searching
-
demonstrate WebTrader as a CoABS grid agent
-
demonstrate WebTrader in scenarios of interest to
DoD
WebTrader alone is not an agent system, but it is
a generalized component capability of most agent systems, providing matchmaking.
The interesting aspect of WebTrader is its scalability to the Web.
Seen in this light, WebTrader can be viewed as a standalone agent grid
enabling component, but one that operates in open WAN environments, is
compatible with not only agent but also object and ontology technologies,
and has no downloading barrier to widespread deployment.
Technical
Accomplishments
Architecture
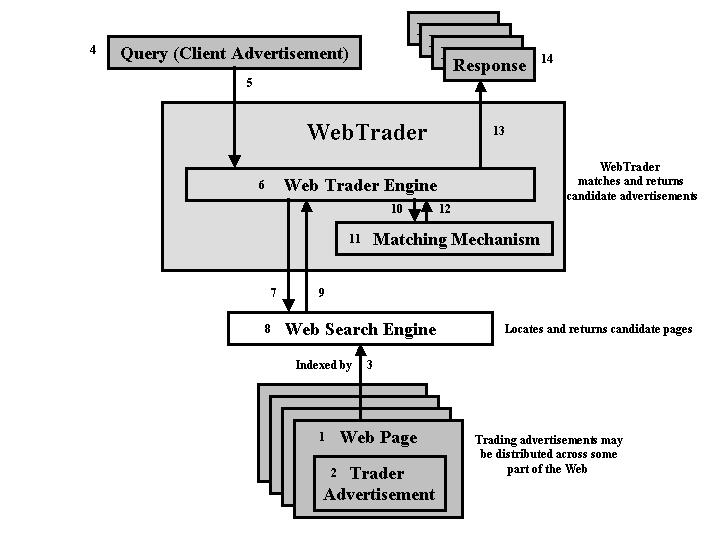
The basic architecture of WebTrader is fairly simple.
Essentially, WebTrader is a new kind of specialized meta search engine
that wraps other search engines to return typed advertisements from the
open Web. As shown in the figure below, any page on the Web (1) can
be annotated by anyone with an XML WebTrader advertisement (2) - see example
Trading
Advertisement DTD. These pages are indexed (3) by ordinary
Web search engines. When a Query (client advertisement) (4) is presented
(5) to WebTrader's engine (6), it accesses known Web search engines (7),
they find matching webpages in the usual way (8) and return then (9).
A WebTrader matching algorithm (10-12) finds candidate advertisements,
scores them, and returns a series of responses in rated order (13-14).
Internet
Resource Advertisements, Trader Federation and Rebinding
Our Salt Lake City demonstration of the WebTrader
(January 1999) illustrated:
-
XML-based resource advertisements
-
service binding and rebinding
-
trader federation
A significant evolution in the design of the WebTrader
ads occurred along the way, as we realized we could rework advertisements
so that resource description in ads could be independently defined, allowing
anyone to create an ad for anything they cared to define or use an existing
definition of, from CORBA IDL components to bicycles. This change
also affected ad matching and returned results. The revised TradingAd DTD
now defines <!ELEMENT resource ANY>, allowing resources to be
any XML document, from reconnaissance reports to parts inventories, from
Java RMI components to Oracle databases. This successfully decoupled
resource definition, basically an ontology question, from the WebTrader
design, a major step forward.
We also made progress on service binding and rebinding
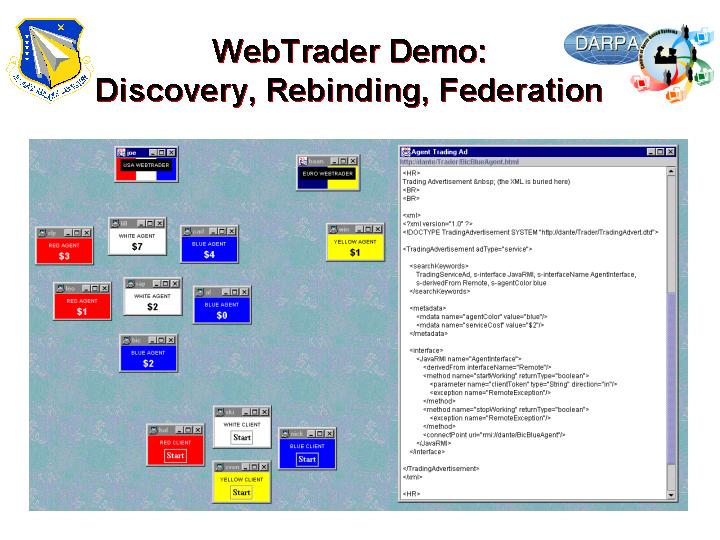
and trader federation. In the Salt Lake City demo, trading ads exist
for a variety of components (e.g., service agents, clients, and WebTraders).
Metadata including color and cost is included into the ads. A Blue
client, for example, asks the USA WebTrader to locate a Blue agents implementing
a particular interface and with zero cost, if possible. One is found
and bound, and the client makes use of the agent. When the agent
unexpectedly dies, the WebTrader is consulted again by the client, in case
the state of the world has changed. It gets back a new list of
agents, sorts them by cost, and goes down the list trying each agent until
it finds one that works. If the WebTrader fails to respond, the client
can fall back on its cached list of previously found agents. When the Yellow
client asks the USA WebTrader for Yellow agents, the WebTraders initial
search turns up none, as it only consults a domain that indexes ads of
Red, White, or Blue agents. However, it does find an ad for a WebTrader
that knows about Yellow agents, and so passes on the original client query
to the Euro WebTrader, which finds a Yellow agent, passes it back to the
USA WebTrader, which passes it back to the client, which then uses it to
connect to the agent. At the right in the figure is shown a service
advertisement in XML. For more detail, see WebTrader
Demo Script.
WebTrader Query
Tool
Our status in Salt Lake City was, we had a better
understanding of both webtrading and also the deep search problem but separate
implementations. The next and main phase of the WebTrader project
was to develop WebTrader Query Tool, a re-designed and re-implemented next
generation WebTrader/DeepSearch capability that combined and generalized
all functionality in a single prototype. This next generation WebTrader
was engineered so that the front-end works as an applet with good performance
on most browsers (tested on Internet Explorer and Netscape) and the backend
is a servlet.
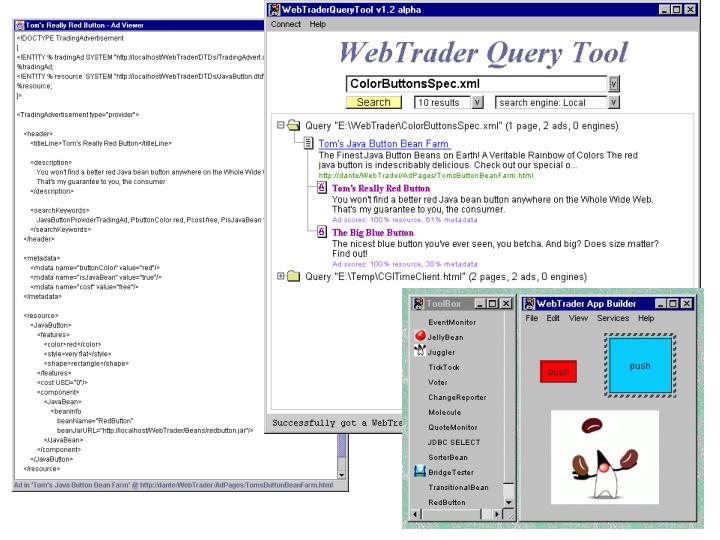
In a demonstration from the CoABS Boston Workshop
(August 2000), WebTrader Query Tool was coupled with a modified Java App
Builder (a visual programming tool), extended with WebTrader drag-and-drop
capability. In the demo, the user creates a want ad called
ColorButtonsSpec.xml, drags it to WebTrader Query Tool, runs a query which
returns pages containing ads for colored buttons, then selected buttons
are dragged to the WebTrader App Builder and connected together to build
a simple application.
WebTrader Query Tool is a generalization, redesign,
and reimplementation of previous work in numerous ways -- the more significant
changes are listed below. Almost all code was rewritten from the
Salt Lake City implementation.
-
advertisements - We redesigned the XML advertisements.
The new design included <!ELEMENT resource ANY> as described
above. We redesigned the WebTrader's JavaRMI DTD (now called JavaRMIObject),
modified its CGI DTD, and modified all the example ad web pages to reflect
these changes. We also created a new ad type (via a DTD) called SiteSearch
to advertise local search engines. We located several local site
search engines that indexed content having to do with agents and manually
created ads for them. Later, we developed heuristics for discovering
unadvertised local search engines on webpages. If found, we include
these as a sub-result of that page and add it to the ad repository - this
kind of discovery is a general approach to populating ad repositories.
-
applet-servlet architecture - We separating
searching from the display the results, and implemented an applet-servlet
architecture. We reimplementing the client-side
GUI as an applet, around 30KB in Java 1.02 for widest portability, about
half for the Tree GUI component. The tree component is
used to record query histories, multiple live searches, canceling and deleting
queries, adding increments to a search (e.g., top 20, 50, or 100
search results. The applet also supports a polling capability
to handle the deep results as well as the top-level ones, scrollbars, and
a concern for efficiency, to reduce the number of messages
between the servlet and applet, so that web-sized scaling of the search
service can be realistically achieved.
-
inputs - WebTrader Query Tool can take either
search terms or want ads as input. We made WebTrader Java Web Start-able,
ie. one can download and run DeepQ as a desktop application with one click.
When run on JVM 1.2 or later, such as via Java Web Start (JWS) or the Java
Plugin, then dragging the WebTrader results over to the Web Trader App
Builder (WTAB) is automatically enabled.
-
target search engines - We developed a modular search engine results
parser and specialized it to Webinator, Google and later to Open Directory.
This kind of thing is an ongoing effort, and not
just with Google, as SEs all seem to tweak their output syntax from time
to time. We redesigned and implemented the match information returned
to clients. Originally we expected to return W3C DOM parse trees
of the XML ad resource to clients as part of this information and build
convience routines for clients to pick out desired information from the
resource (such as the URL of a Java RMI object to connect to to get the
service advertised in the ad). However, the DOM objects generated
by Sun's XML parser are not (directly) serializable and thus not able to
be sent through the RMI link the WebTrader uses between its client and
server parts. So, instead we return the raw XML of the resource and
use SAX-based XML parsing tools on the client side to accomplish the same
thing, a better design since we are sending less information and SAX is
lighter weight than DOM. Later, we developed an algorithm
to accurately parse the results of foreign search engines encountered on
the fly (or fail safely).
-
matchmaking algorithm - We modified the WebTrader
metadata matching algorithm to more successfully match metadata dynamically
created from user inputted search keywords. Also, we ideveloped a
generic scoring model.
-
federation - We developed a new WebTrader
federation design. One insight from the new design of the WebTrader
federation scheme is that a WebTrader does not have to wait to determine
that it cannot find any or enough matches to satisfy a client; at any point
it comes across an ad for another WebTrader that looks promising it can
propagate its query to it, and have all the results dynamically merged
(sorted) on the client end. In fact, there is probably not any other
practical way - what WebTrader has time for secondary WebTraders (and so
on) to build up a list of results - all results must be streamed dynamically
to be timely.
-
performance - We implemented a new result
polling capability. Now all search engines are equally controllable
from the applet, instead of special consideration given to the top level
engines in the old design. Now, the GUI will not keep up constant
connection to servlet, but will rather poll for results.
-
security - We modified the applet GUI to better
work as a JWS app for the situation where there is no web page that the
applet is embedded in.
Gridifying WebTrader
The CoABS grid is a JINI-based implementation
of an agent interoperability platform developed by GITI, the DARPA CoABS
program integration contractor. It is an important, on-going experiment
in agent system interoperability. As described elsewhere, we contributed
architectural ideas to the grid. But in addition, we developed three
standalone agent components (eGents, WebTrader, and AgentGram) that can
play a role as (stand alone or connected) grid components or services.
As part of the Agility WebTrader project, we developed the grid-relevant
capabilities described below. At the same time, we note that WebTrader
is itself a potentially pervasive stand-alone grid capability that can
supply matchmaking for agent, object or ontology systems.
For the Science Fair (October 1999), we gridified the WebTrader Agent
(WTA). Previously, in NEO TIE #2 (see description below), the WebTraderAgent
(WTA) was used as a WAN matchmaker to provide SRI OAA and USC/ISI
Ariadne the ability to dynamically extend its information sources based
on user queries it received. For the Science Fair, we modified the
WTA to query the Grid for any WebTraders registered there. If none
is found (or timeout), then the WTA automatically falls back to its local
embedded WebTrader. This essentially extends CoABS grid JINI lookup
service to be a WAN lookup service. The implementation involved creating
the WebTrader Grid Service (WTGS), a Java program that registers a WebTrader
on the CoABS Grid and logs its actions, along with a new version of WebTrader
Agent (WTA) that lists WebTraders found on the Grid. We worked with
Hank Seebeck and Adam Wenchel (both GITI) to test WTA on the grid.
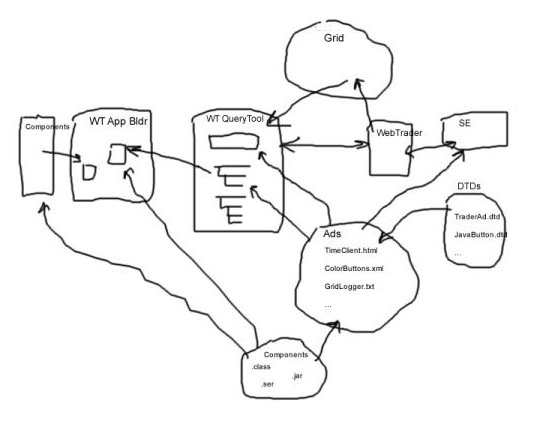
For the Boston CoABS Workshop (August 2000), we upgraded WebTrader Query
Tool to use the grid in the same way as shown in the diagram below.
We also created a launch page for a CoABS 7x24 grid accessible version
of DeepQ. WTA was maintained on the CoABS 7x24 grid for approximately
a year.
Technology Transition
In 1999, we applied WebTrader in the DARPA CoABS Non-combatant Evacuation
Order (NEO) Technology Integration Experiments (TIE). The
NEO
TIE involved an urban rescue effort and served to organize many CoABS program
activities in the first year of the CoABS program. The thrust was
on agent interoperability and rapid assembly of heterogeneous agent systems
to solve problems. Lessons learned and components from this exercise
where later incorporated into the CoABS grid. TIE
#2 involves the scenario Find
Civilians, Get Them to Embassy, and the interaction scenario below
shows not only what information is required but also the role of various
CoABS subsystems: OBJS WebTrader, OBJS AgentGram/MBNLI, ISI Ariadne
(which extracts information from Web pages), and SRI Open Agent Architecture
(OAA, which enables inter-agent communication). Steve Minton (ISI)
coordinated the TIE. For the NEO TIE, we developed WebTraderAgent,
an OAA wrapper for a WebTrader. This effectively added a Web-wide
trader to OAA. In the demo, when a new service or data source is
needed, the WebTraderAgent is consulted to locate a WebTrader which can
then be consulted to locate advertisements for matching services.
In addition to building the OAA wrapper, this involved porting WebTraderAgent
to JDK 1.2 (Java 2), creating a stripped-down security policy for WebTraderAgent,
and using an executable jar file to house the agent.
In March 2000, we presented work on Agent
Discovery Matchmaking to OMG, essentially, a sketch of a reference
model for traders that subsumes WebTrader as well as conventional agent
matchmakers and LAN traders like OMG's Trader.


Next Steps
The main puzzle preventing widespread use of WebTrader is the problem of
populating the Web with advertisements. Since advertisements can
be about anything, this is essentially the ontology problem. The
entire DARPA DAML program as well as W3C RDF and semantic web communities
are working this problem. Universal Description, Discovery, and Integration
(UDDI) has recently been working to register businesses and their services.
Finally, various Want Ad repositories have developed interesting proprietary
ontologies. Since WebTrader's architecture is relatively independent
of resource descriptions, the architecture can use any or several of these
ontology representations. Both DAML and UDDI are examples of manually
creating advertisements. An alternative is to automate this process
(insofar as possible). A potential source of ads is the Web itself,
namely, mining Web pages for ads of interest, especially in tractable domains.
Alta Vista has done this with various easy-to-recognize data types like
images and mpg's. It might not be hard to find certain other kinds
of elements, for instance, banner ads. Similarly, our DeepSearch
project has developed ad hoc recognizers for locating local search engines
on Web pages. Of course, both manual and automated means of populating
the ad space would be useful.
It is worth noting that the basic design of WebTrader appears to be
that of an open world repository, that is, ads can come from any
pages that search engines index. Interestingly, it is not a large
change to convert WebTrader into a closed world search engine only
containing ads that are inserted into its database (instead of SE index).
This might make more sense for some kinds of services, e.g. resume services
or a company's web services, where the service provider might want control
over who can advertise.
Although robust in several ways, the WebTrader implementation is still
a prototype. More work is needed in several areas:
-
We would like to explore type specific matchmaking
so different matchmakers could be plugged into WebTrader on-the-fly depending
on the type of advertisement. We ran into this requirement in the
NEO TIE where it would have been useful to match the predicate, the arguments,
and the variables in OAA solvables so only exact matches would be found
-
We need more work on the algorithm for parsing results of search engines
to extend the meta search capability.
-
For many purposes, it makes more sense to index advertisements
during the crawling phase rather than when pages containing ads are returned
from search engines.
-
We would like to remove the dependence on Thunderstone's
Webinator which requires a live Internet connection (so it can check the
online license at Thunderstone), does not always rank the results of OR
queries correctly, does not support some of the query logic we need, and
does not index XML pages. Open Directory ISearch is a potential alternative.
-
We would like to use toolkits flike WEBL and XWRAP
Elite for web page content extraction as a way to locate SEs on web pages
faster.
This research is sponsored by the Defense Advanced Research
Projects Agency and managed by the U.S. Air Force Research Laboratory under
contract F30602-98-C-0159. The views and conclusions contained in this
document are those of the authors and should not be interpreted as representing
the official policies, either expressed or implied, of the Defense Advanced
Research Projects Agency, U.S. Air Force Research Laboratory, or the United
States Government.
© Copyright 1998, 1999, 2000, 2001 Object Services
and Consulting, Inc. All rights reserved. Permission is granted
to copy this document provided this copyright statement is retained in
all copies. Disclaimer: OBJS does not warrant the accuracy or completeness
of the information in this survey.
Last revised: October 2001. Send comments
to
Craig Thompson.
Acknowledgements: Paul Pazandak did most of
the design and implementation with Craig Thompson providing brainstorming
and review. Steve Ford installed and demoed MBNLI at CoABS Workshops
that Pazandak did not attend. Thompson completed the CoAX TIE demo.