The purpose of this position paper is to describe the state of the practice in Web and distributed object integration by describing research in this area at Bellcore. We present below the results of an intensive prototyping effort that was conducted in order to assess the suitability of a number of middleware technologies for providing Web access to a wide variety of legacy systems. Our goal was to provide a unified user interface that could transparently access different legacy systems without the user being aware of the types of back-end systems being accessed. We also experimented with scenarios where a single user query results in interaction with multiple legacy systems and consolidated results are presented to the user. The approach allows plug-and- play - i.e. clean interfaces are defined for plugging in any number of legacy systems transparently.
The interface between healthcare providers and insurance companies is provided by an object, called the Payer object. The Payer object represents a single insurance company, or payer. The object interface allows healthcare providers to check the eligibility of patients for insurance coverage, submit insurance claims, and check the status of submitted claims. The object interface is described using CORBA IDL.
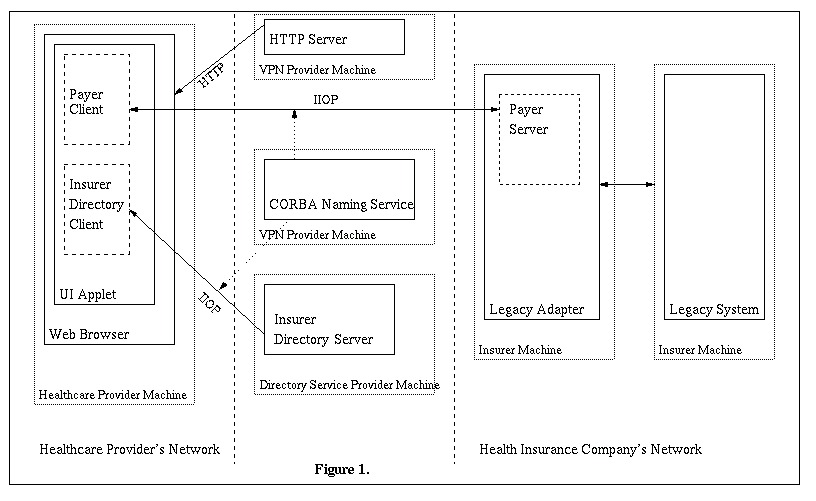
Client User Interface Applets
The client GUI interface for the healthcare provider is contained in a set of Java applets. An HTML link in a menu of operations leads the user to the required applet. The user then downloads an applet (by clicking on an HTML link) from a Web server using a Java-enabled browser. The applet contains a CORBA Payer client, implemented using IONA's OrbixWeb 2.0.1, that communicates with a Payer server.
Payer server
This CORBA server, implemented using IONA's OrbixWeb 2.0.1, receives requests from a Payer client, and needs to access legacy data in order to respond to these requests. The legacy system is accessed by the Payer server using technology appropriate for the specific legacy system.
Legacy System
Patient and claims data is stored in some legacy system in the health insurance company's network. The different legacy systems that we used are described below:
MVS mainframe: The back-end system storing insurance information is an MVS mainframe system. We built the Payer object on MVS by storing it in an IMS data store. We then implemented methods in the REXX language to perform the three Payer object operations. In order to invoke these REXX methods, we needed to make use of a screen scraper (Apertus' Enterprise/Access). Thus our Payer server relays requests received from the Payer client to the Enterprise/Access screen-scraping software.
ODBC-enabled database: Insurance data is in an ODBC-enabled database. Functionally, the system consists of a Payer server (the front-end interface) and an ODBC client (the back-end interface). The Payer server receives CORBA calls and makes ODBC calls to an ODBC driver manager to make SQL queries to the database. The only knowledge of the database the Payer server has is the database schema and access requisites (such as login name and password). This means that exactly the same server could be used with a non-legacy incarnation of the same or expanded database, as long as the database schema remains unchanged. This, along with the prohibitively high (for this experiment) cost of a DB2 ODBC driver for MVS, led us to use an Oracle database in place of a true legacy database. jet.connect, a Java ODBC class library from XDB Sys tems, is used to make ODBC calls inside the Payer method implementations. DataDirect ODBC driver manager and Oracle driver for Solaris from Intersolv and an Oracle 7.3 database server have been been used for the remaining components. All of the components are running under Solaris 2.
Transaction Integration: We extended the healthcare example by implementing a scenario where there is a need for a transaction to span across multiple healthcare providers. Say a patient has insurance coverage from two different health insurance companies. When a claim is submitted for this patient, the claim submission needs to be sent to both companies, and should either fail or succeed at both locations. We implemented transaction integraton using IONA's Orbix OTS, an implementation of OMG's Object Transaction Service.
SNMP data: We also provided Web-based access to SNMP management information via CORBA interfaces (note that the Payer object was not used for this as management data is different from application data). Two steps were required for this: first, translate the relevant SNMP MIBs (Management Information Bases) into CORBA IDL. This was done using the X/Open Joint Inter-Domain Management translation algorithm [2]. Second, build a gateway that will convert CORBA method invocations into SNMP PDUs (Protocol Data Units) and vice-versa. We implemented a CORBA-SNMP gateway using IONA's Orbix 2.2MT. This version of Orbix uses an IDL to C++ mapping. The implementation of the CORBA interfaces was done in C++. On the client side, the implementation was done using IONA's OrbixWeb 2.0.1. We also made use of an SNMP toolkit that is available as freeware from CMU [1]. We then built a C++ object wrapper around the CMU toolkit that would hide the details of the SNMP protocol from the developer.