WebTrader: Discovery and Programmed Access to Web-Based Services
Venu Vasudevan 1 and Tom Bannon 2
{venu, bannon}@objs.com
1 Object Services and Consulting Inc., 1942 E. Todd
Drive, Tempe, AZ 85283
2 Object Services and Consulting Inc., 5111 Purdue Ave.,
Dallas, TX 75209
Abstract
As more and more services become web-enabled, the web needs a
service trading infrastructure to automate the discovery
of and access to web services. Without this infrastructure, we are limited
to accessing services in isolation via interactive front ends. An effective
service discovery infrastructure will enable the construction of applications
that are dynamic ecologies of web components. Platform specific traders
have been implemented in AI and distributed object architectures, but are
not capable of catering to the diversity of web service implementations.
This paper describes the design and implementation of WebTrader, a trader
that handles the heterogeneity, scalability and evolution in a web-based
service market.
Keywords
web searching; agents; service discovery; web automation; trader;
crawler; metadata
1. Introduction
The web is rapidly transitioning from a document repository to an open
service market supporting large numbers of globally accessible services.
The transition is driven specifically by the growth of e-commerce,
and more generally by a push towards the web as a worldwide computational
platform [Kini96, Vahd98]. Web services
are currently accessed interactively and in isolation via web page front-ends,
as the web lacks an infrastructure to support service discovery and
programmed access. The addition of a service discovery and access service
(a.k.a. trader) [OMG96, Deck97]
will enable complex applications to be architected as dynamic ecologies
of interacting web agents.
While traders resemble document search engines in that they address
a search problem, document search engines are inadequate to solve the service
search problem for several reasons. Current search engines support
keyword-based querying and indexing of information. Keyword-based service
descriptions cannot capture such aspects of service delivery as location,
access methods, access semantics, information quality and cost. Secondly,
search engines are designed for human interaction, and do not allow client
programs to specify the distance functions and filtering criteria to be
used in soft matchmaking. Lastly, the impact of outdated index information
is more serious in the case of service trades than it is on document searches.
For instance, outdated cost information about a service can cause a client
to pay more than anticipated for a service. Document search engines do
not provide any means for a client to specify the quality and certification
level of the index information it wants to use in a service search. These
are some reasons why service discovery needs a specialized search tool.
A number of applications can benefit from a service discovery framework
such as that provided by a web trader. To consider just a few:
Application-Level Brokers
Application-level brokers provide value-added services that
are layered over "feeder" services. Instances of such brokers include comparison
shoppers [Junglee, Entry
Shopper] that search several instances of the same feeder service type
(e.g. an online shop, mortgage provider etc.) to find the cheapest shirt
or the best mortgage rate. Application brokers might bridge instances of
dissimilar services (e.g. a stock technical analysis service and
a stock insider trading service) and compose the retrieved information
to provide a value-added capability (in this case, to recommend a "screen"
of suitable stocks to purchase). Application-level brokers require traders
to gain programmed access to appropriate feeder services, and to be able
to discover new instances of feeder services as they come online.
Adaptive Content Delivery
Given the growing diversity of web-enabled end-user devices,
web information needs to be adapted to the capabilities of the device used
by the information consumer. For instance, it is desirable to elide the
images from a document before delivering it to a web-enabled cell phone.
A solution is to design the information adaptation smarts into the
network, whereby the network dynamically inserts network elements
between the web server and the web client to perform the appropriate content
distillation [Fox96]. A trader is needed to find the
right network elements for a given combination of information content and
end-user device.
Application Recontexting
Applications on mobile devices will be thin, and maintain only
the minimal amount of application logic on the device. They will depend
on their computational environment for support services, with the web itself
being a global, omnipresent computational environment. Recontexting
refers to the process by which a thin client application finds and interfaces
with the necessary support services in changing contexts (as the user moves
in and out of different situations and environments). [Hode97]
illustrates a scenario where a "visitor agent" application on a university
visitor's palmtop interfaces with local map services, room control and
projection devices to help the visitor deliver his talk. Application recontexting
requires access to federations of locale-specific traders that can provide
local service information, and hand-off a mobile user to the next locale
[Hull97].
Trader architectures have been proposed as part of distributed object [OMG96]
and AI [Deck97] architectures, and there is a rich space
of architectural choices in trader design. However, none of these traders
is well suited to address the scalability, heterogeneity and evolution
of a web-based service market. This paper describes the design and implementation
of WebTrader, a trading service for locating and accessing other
web services. First, we expand on trader concept, and describe the
design choices in a trader architecture. Next, we discuss the appropriate
choices in a trader "of and for the web". Third, we present details of
the WebTrader implementation, and a usage scenario. Finally, we discuss
related work and the future of our approach.
2. Trader Architectures
2.1. Overview
Traders mediate between clients and services, thus providing a loosely
coupled architecture where the binding between service and client is dynamically
(re)established (Figure 1 shows the message flows). Services publish their
capabilities and availability by registering service advertisements
with the trader (a.k.a exporting to the trader). Service advertisements
contain one or more service handles (multiple handles for multi-portal
services) and an offer descriptor. The offer descriptor describes
a service offer in terms of the service type description (including
access methods), and a set of named properties that capture
unique characteristics of the service instance as (name,value) pairs. Service
characteristics that are described in instance properties may include the
geographic location of a network gateway service, the fidelity and accuracy
of an interactive map service, service cost and payment options of a stock
advisory service, and the languages supported by a text-to-speech translation
service. A client queries the trader by supplying a service template
(a.k.a imports service descriptors from the trader). In response,
it receives a collection of matching service descriptors. The service template
specifies the desired service type, and property predicates representing
the selection criteria for service instances.
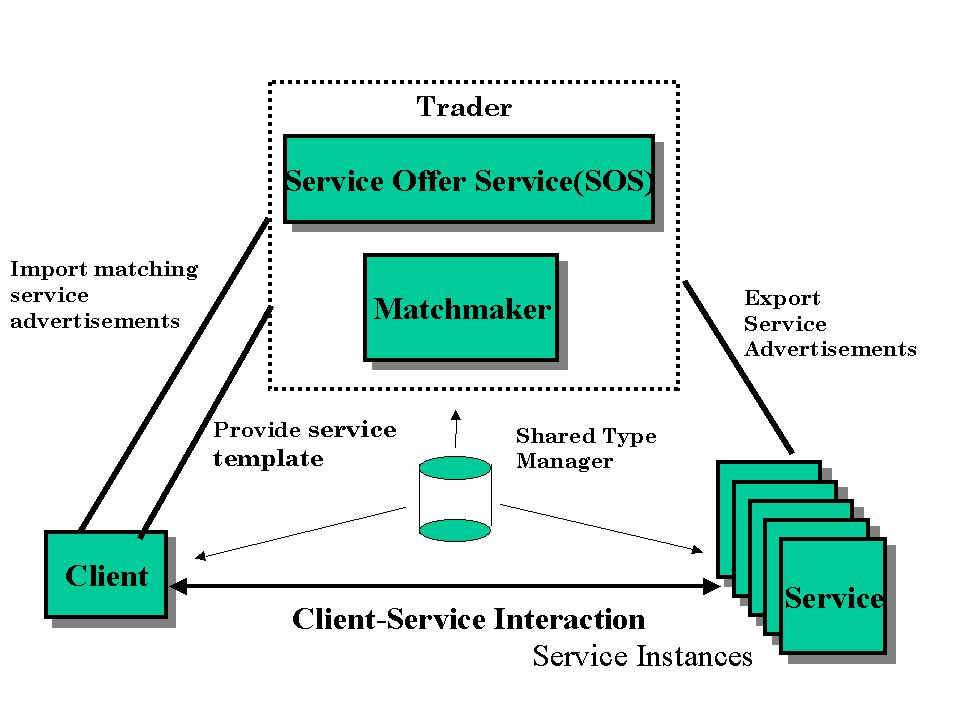 Figure
1: Interaction between a trader and clients
Figure
1: Interaction between a trader and clients
Trading functionality is differentiated into modules for type management,
service offer management and matchmaking. A type management module
supports and provides access to a common type model that is shared between
clients, traders and services. A service offer service (SOS) provides
a publication API for services to publish service advertisements, and a
query API for other modules to retrieve selected advertisements. A matchmaker
provides a soft matching capability by which the trader determines
the service descriptors that best match a service template. As trader
service models are more structured than web document models, the matchmaking
heuristics are more specialized, structured and domain-dependent than those
of document search engines. As mentioned earlier, matchmakers superficially
resemble search engines but perform a more structured search. Consequently,
the matchmaking heuristics in a trader need to model the vocabularies,
distance functions and equivalence classes in a domain-specific property
space, in contrast to the keyword-based, domain-neutral matchmaking supported
by document search engines.
A single trader is unlikely to scale to the internet due to scoping
and performance issues. A trader needs access to the offer space that it
trades with, and it is unlikely that a single trader will get access to
every service advertisement on the internet. Even if such access were possible,
traders may want to specialize in the type of advertisements they handle
and the performance they guarantee. These reasons motivate the need for
trader federation schemes that allow multiple traders to partition
and contextualize an offer space, allowing the trade computation
to be distributed and specialized across multiple traders.
2.2. Design Space
While all proposed trader designs share the architecture described above,
they differ in the kinds of services they trade with, the manner in which
they acquire service advertisements, the type model they support, and the
federation approach they use to scale up trading function. We now describe
this design space of choices, and the tradeoffs in making a particular
choice. A more detailed design space is described in [Venu98a].
-
Trade Heterogeneity. Trader designs place different constraints
on the protocols supported by the services they trade with. Homogenous
trader designs expect the service instances they trade with to support
a single access protocol (and therefore a single kind of service handle).
The OMG trader service is a homogenous trader which requires all traded
service instances to have CORBA handles. Heterogeneous traders trade
accommodate multiple service access protocols, and can deal with multi-portal
services that export their capabilities via multiple protocols. Heterogeneous
traders are more suited to an open service market, where the protocols
for service provision are continuously evolving. Conversely, heterogeneous
trading adds complexity to the type management approach.
-
Type Management. Trading requires clients, service instances and
the trader to share a type domain, i.e. have a common understanding
of types and their capabilities, and of inter-type relationships (e.g.
type hierarchies). Such type management can be centralized or decentralized.
CORBA ORBs are an example of the former, in that a centralized type
repository manages type information. The CORBA trading architecture
requires the client, trader and service instance to access the same, platform-specific
type repository. Centralized type management typically constrains the trading
to be homogenous, as the type repository is only accessible via a single
protocol. Decentralized type management approaches adopt the philosophy
of "type as data". That is to say, type information is metadata, and metadata
is data. The web (e.g. XML and RDF) exemplifies the decentralized type
management approach, where type information that describes a document's
structure is included as data in the document. Decentralized type management
does not preclude type repositories, as types can be shipped either by
value (copied in with instance information), by reference
(multiple instances maintain hyperlinks to the same type repository "document"),
or by a hybrid approach.
-
Offer Acquisition. Traders may acquire service advertisements
by means of push or pull. In push schemes, service
instances (or their proxies) invoke methods on the trader object to advertise
their capabilities. The OMG trader uses a push scheme whereby service
instances are responsible for publishing their advertisements to the trader.
Pull schemes transfer the responsibility of collecting service advertisements
to the trader. In a semi-automated pull, both the service
instance and the trader play a role in getting the advertisement to the
trader. The service instance publishes the advertisement to an SOS, but
the advertisement is automatically downloaded by trader(s). In an automated
pull scheme, the trader takes care of constructing the service advertisement
by directly interacting with the service, thus requiring no participation
from the service instance in either creation or retrieval of the service
advertisement. In such a scheme, a servicebot (analogous
to a search engine robot) is responsible for the discovery and characterization
of web services.
-
Trader Federation. Cooperating traders can federate
using either repository-based approaches (ad shipping) or explicit
delegation (trade shipping). In ad shipping, multiple traders share
service advertisements by accessing a common SOS. An advertisement published
to this SOS can be retrieved by any trader that has access to the SOS.
In trade shipping, SOS'es are encapsulated and hidden inside traders, and
the inter-trader cooperation happens by traders explicitly forwarding trade
requests to other traders. Trade shipping requires contractual arrangements
between members of a trader network, and mechanisms to avoid "passing the
buck" (cycles in the trader graph). Trade shipping is complex to setup
and better suited to small, static trader graphs. Trade shipping is especially
useful in architectures (e.g. the CORBA architecture) which do not support
global repositories.
Figure 2 below contrasts the two approaches. In trade shipping, the
service offers are partitioned between traders. The propagation of a trade
request through the trader graph is determined by links and trader
attributes. Links represent high-level contractual agreements
between traders. Given a link between two traders, trader attributes determine
the kinds of advertisements that are propagated along that link. Attributes
are used to limit the number of hops a trade request can make, and to avoid
cycles. In ad shipping, the objects that are forwarded are advertisements,
not trade requests. Traders that share access to an SOS could potentially
view all the advertisements contained in the SOS. Trader attributes determine
the advertisements each trader chooses to normally deal with, and the alternate
SOS'es that a trader might use to expand a search.
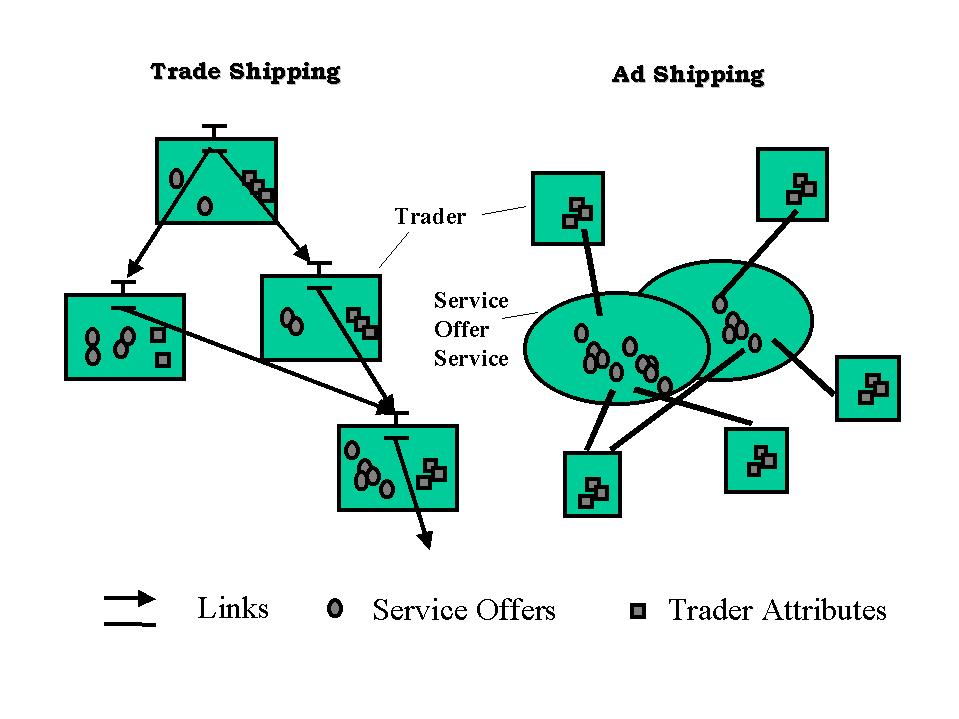
Figure 2: Approaches to Trader Federation
3. Web-Friendly Design Choices
Services on the web are implemented in a variety of ways including CGI
scripts, servlets, IIOP-accessible CORBA objects, and Java RMI-based components.
Rather than predict the evolution of such an open service market, a web
trader needs to be heterogeneous to accommodate the variety and
evolution in service access mechanisms. Platforms encode and manage
type information in different, platform-specific ways. Type information
about CORBA services is encoded in the Corba-IDL language, and managed
by a CORBA-compliant type repository. Java services do not have a standardized
type repository, although type information can be extracted from a component
using Java reflection. Services that are CGI scripts do not encode
the semantics of the service at all, unless the service provider has documented
this in some informal manner. Consequently, services handled by the trader
use diverse type models that are different in small but significant ways.
A web trader needs a platform-neutral, machine interpretable mechanism
to encode the capabilities of such heterogeneous services in a uniform
manner. Further, the trader cannot mandate that all this type information
be available in a single type repository, as such an approach would not
scale up to the web. Decentralized type management is more
appropriate for web service markets, where type information is encoded
as distributed documents, and collected by crawlers or other web automation
scripts.
| Design Issue |
Approach |
Contrasting Approach |
| Scope of services that are traded |
Homogenous |
Heterogeneous |
| Type Management |
Centralized |
Decentralized |
| Offer Acquisition |
Push |
Pull (semi-automated
or automated) |
| Trader Federation |
Trade Shipping |
Ad Shipping (or hybrid) |
Table 1. Trader design choices (web-friendly choices are colored
blue)
Approaches to offer acquisition and inter-trader federation need to leverage
search engines that provide an ubiquitously available and readily
searchable repository. Search engines provide an off-the-shelf implementation
of an SOS, in that they support the storage and querying of service
advertisement pages (SAP). Publishing an SAP to a search engine amounts
to exporting the service to traders that access this search engine. As
search engine robots are not capable of extracting SAPs from service instances,
the offer acquisition is a semi-automated pull scheme where the
advertisement is still created manually by the service provider but automatically
retrieved by trader(s). The accessibility and query support in search engines
make ad shipping a natural choice for federating web traders.
Table 1 above summarizes the design space discussion from section 2.2,
highlighting (in blue) the choices that make
sense for a web trader.
4. Implementation
We first describe the implementation of WebTrader, a web-based trader that
uses a search engine as the SOS for service advertisements. This discussion
assumes that all WebTrader instances have access to a single well known
search engine. Subsequently, we describe DeepSearch, a scheme that allows
traders accessing one search engine to become aware of advertisements indexed
by other (semi)-private search engines.
4.1. WebTrader
WebTrader defines both service advertisements and service templates as
XML objects that are embeddable in HTML pages. The XML DTD for a
service advertisement (Figure 3a) has three sections:
interface, metadata (properties) and searchKeywords.
The interface section describes an operational interface in terms of its
type and location. A service advertisement can have multiple interfaces
(for multi-portal services) and the fact that a service interface can be
available at multiple locations (e.g. mirror services) is modeled using
multiple connectPoint elements in a single interface. The fact that
a service instance conforms to an interface specification is modeled explicitly
in XML, rather than using platform-specific mechanisms such as CORBA IDL
for the purpose. The availability of such type information as XML data
allows WebTrader to be apply the same matchmaker across different protocols.
The metadata section allows sets of instance-specific service properties
to be specified as name-value pairs. As mentioned before, an XML-based
service advertisement is embedded in an HTML service advertisement page
(SAP) to be accessible to search engine crawlers. An XML service advertisement
is thus an embeddable HTML object and may be transported in HTML pages
that are unrelated to the service advertisement. The searchKeywords
section provides keywords that are to be used by the search engine to access
the SAP. In cases where the crawlers support HTML META tags, the terms
in the searchKeywords section are replicated as META tags in the SAP.
<?xml version="1.0" ?>
<!DOCTYPE TradingAdvertisement SYSTEM "http://www.objs.com/WebTrader/TradingAdvert.dtd">
<TradingAdvertisement adType="service">
<searchKeywords>
TradingServiceAd, s-interface
JavaRMI, s-interfaceName
RMITimeService, s-derivedFrom
Remote, s-clockResolution
seconds, s-serviceCost
free,
</searchKeywords>
<metadata>
<mdata name="clockResolution"
value="seconds"/>
<mdata name="serviceCost"
value="free"/>
</metadata>
<interface>
<JavaRMI name="RMITimeService">
<derivedFrom interfaceName="Remote"/>
<method name="getTime" returnType="String">
<parameter name="timeZone" type="String" direction="in"/>
<exception name="RemoteException"/>
</method>
<connectPoint uri="rmi://www.objs.com/RMITimeServer"/>
</JavaRMI>
</interface>
</TradingAdvertisement>
Figure 3a: A WebTrader Service Advertisement
The fact that service advertisements are human-readable (and editable)
pages helps in advertisement creation and debugging. Complex services (e.g.
a map service), all of whose attributes are hard to capture as properties,
can embed a sample output as part of the advertisement. Showing a sample
map produced by the map service provides a simple (perhaps interim) alternative
to quantifying the QoS properties of map services in some universally agreeable
fashion. Clients can annotate SAPs with comments as to whether the properties
of a delivered service match those advertised in the SAP. These annotations
could be used by either the advertiser or the trader to correct a service
advertisement.
<?xml version="1.0" ?>
<!DOCTYPE TradingAdvertisement SYSTEM "http://www.objs.com/WebTrader/TradingAdvert.dtd">
<TradingAdvertisement adType="client">
<searchKeywords>
TradingClientAd, c-interface
JavaRMI, c-interfaceName
RMITimeService, c-derivedFrom
Remote, c-clockResolution
seconds, c-serviceCost
free,
</searchKeywords>
<metadata>
<mustHave>
<mdata name="clockResolution" value="seconds"/>
</mustHave>
<reallyWant>
<mdata name="serviceCost" value="free"/>
</reallyWant>
</metadata>
<interface>
<JavaRMI name="RMITimeService">
<derivedFrom interfaceName="Remote"/>
<method name="getTime" returnType="String">
<parameter name="timeZone" type="String" direction="in"/>
<exception name="RemoteException"/>
</method>
</JavaRMI>
</interface>
</TradingAdvertisement>
</xml>
Figure 3b: A WebTrader Client Service Template
A client service template (a.k.a "client
advertisement", see Figure 3b) shares the same DTD as service advertisements,
but uses additional tags to specify type and property predicates. The mandatory
and preferred tags in the metadata section allow a client to specify
hard requirements and relative priority of different property predicates
in the matchmaking process. The interface section allows a client
to partially specify the type signature of the required service type.
In addition to retrieving instances of an explicitly named service type,
a partial type signature allows clients to partially specify the desired
type by stating its derivation, or by specifying that the type support
particular method(s). Without knowing the type name of internet time services,
a client could then retrieve instances of time services by querying
for all service instances that have a method named getTime.
The WebTrader is accessible via CGI and RMI URLs.
The code snippet below illustrates RMI-based access
to a WebTrader, and subsequent access to the retrieved service instance.
// Get a handle to the WebTrader
String traderURL = "rmi://www.objs.com/WebTrader";
Trader trader = new Trader (traderURL);
...
// Use the trader to find a service for our needs
String ourURL = "http://www.objs.com/WebTrader/RMITimeClient.html";
TraderMatch matches = trader.getMatches (ourURL, 1); // only
get 1 match
...
// Link to the time server we got from the trader and get
the time
ConnectPoint connectPoints[] = matches[0].getConnectPoints();
String url = connectPoints[0].getUri();
RMITimeService rmiTime = (RMITimeService) Naming.lookup (url);
String time = rmiTime.getTime (timezone);
...
Figure 3c: RMI-based trader access API
4.2. DeepSearch
The discussion above assumes that traders exchange advertisements via a
single well-known search engine, and that all service advertisements are
accessible by this search engine. What we have in reality is not a single
search engine or a small, flat space of a few global search engines, but
a hierarchical space with large numbers of local search engines whose scope
may be a single web site, a single department, or an enterprise.
DeepSearch supports the federation of these search engines, allowing
advertisements to propagate selectively within the search engine hierarchy.
DeepSearch can be thought of as federated ad shipping, analogous to OMG's
federated trade shipping scheme based on inter-trader links. DeepSearch
treats a search engine itself as a special kind of service, and supports
superlinks, which are XML advertisements by search engines to other
search engines. A search engine X advertises its existence to search engine
Y by publishing a superlink page to Y. Traders that access search engine
Y can now retrieve the superlink in addition to normal SAPs. A client may
request that a trader match its service template against directly available
advertisements, or that it also include advertisements that are retrievable
by following one or more superlinks. On-demand activation of superlinks
allows the client (and the trader) to tradeoff speed of matchmaking versus
its precision and recall.
5. Discussion and Related Work
In this paper, we described the problem and design space of web service
trading, and the implementation of WebTrader, a lightweight trader implementation
that leverages search engines and XML to support service trading.
Areas which we plan to investigate further are smarter matchmaking, automating
the creation of web service advertisements, further work on trader
federation architectures, and the use of WebTrader to support end-to-end
properties of a binding.
While WebTrader supports matches across a variety of service protocols,
its matchmaking approach is based on strong signature matching between
a client service template and the service advertisement. We will investigate
ways of matching client requests that are expressed in a looser, more function-oriented
vocabulary (e.g. a set of domain terms). Another area that is time
consuming at present, is the manual creation of service advertisements.
We will investigate the use of servicebots to (partially) automate
the extraction of service advertisements. Depending on the complexity of
the services, servicebots may be resemble traditional web crawlers [Seac98],
or incorporate significant machine intelligence and learning capabilities
[Etzi97]. Unlike crawlers, service discovery will require
families of servicebots, each specialized in some fashion. Protocols are
an obvious dimension of servicebot specialization, as extracting a Java
RMI advertisement (using reflection) is different from extracting CORBA
ads (using IDL interface repository querying) which is different from interrogating
a service implemented as a web server servlet. Servicebots will also use
different heuristics to deduce (and confirm) service signatures of interactive
services (e.g. online shops) whose access methods are hidden on their home
page and need to be extracted by page scrubbing (i.e. parsing an
HTML page for hidden CGI access methods). Finally, while this paper has
focussed on the discovery of a single matching service instance to satisfy
a service request, multimedia QoS and document distillation applications
provide scenarios where the trader needs to match a client request to a
binding that strings multiple services together. This requires a
compositional trader [Venu98b] which accepts a client's
service template and matches it not to a single service instance but to
an assembly of multiple services.
References
-
[Deck97] Decker,K., Williamson,M. and Sycara,K., Middle
Agents for the Internet, In Proceedings of IJCAI-97.
-
[Etzi97] Etzioni,O., "A scalable comparison-shopping
agent for the World Wide Web", In Proceedings of Autonomous Agents '97.
-
[Fox96] Fox, A. and Brewer,E., Reducing
WWW Latency and Bandwidth Requirements by Real-Time Distillation, In
Proceedings of the Fifth International World Wide Web Conference
-
[Hode97] Hodes,T.D. et al., Composable
Ad hoc Mobile Services for Universal Interaction, UC Berkeley BMRC
Technical Report, 1997.
-
[Hull97] Hull,R. et al., "Towards Situated Computing",
HP Labs Technical Report, HPL-97-66, 1997.
-
[Kini96] Kiniry et al., Leveraging
the World Wide Web for the World Wide Component Network
-
[OMG96] OMG Trading
Object Service
-
[Rose97] Rosenberg,J. et al., IETF
Draft on Wide Area Network Service Location.
-
[Seac98] Seacord,R., Duke
ORB Walker, Workshop on Compositional Software Architectures, 1998.
-
[Vahd98] Vahdat,A. et al., WebOS:
Operating System Services For Wide Area Applications, to appear
in the Seventh Symposium on High Performance Distributed Computing, 1998.
-
[Venu98a] Vasudevan,V., A
Reference Model for Trader-Based Distributed System Architectures,
OBJS Technical Report, 1998 (see URL).
-
[Venu98b]Vasudevan, V., Trading-Based
Composition for Component-Based Systems, Workshop on Compositional
Software Architectures, 1998.
URLs
This research is sponsored by the Defense Advanced Research
Projects Agency and managed by the U.S. Army Research Laboratory under
contract DAAL01-95-C-0112. The views and conclusions contained in this
document are those of the authors and should not be interpreted as necessarily
representing the official policies, either expressed or implied of the
Defense Advanced Research Projects Agency, U.S. Army Research Laboratory,
or the United States Government.
© Copyright 1998. Object Services and Consulting,
Inc. Permission is granted to copy this document provided this copyright
statement is retained in all copies. Disclaimer: OBJS does not warrant
the accuracy or completeness of the information on this page.
Last Revised: December 1998