Paul Pazandak , Craig
Thompson
Object Services and Consulting, Inc.
The architecture we present is an enabling technology which facilitates
the dynamic augmentation of applications with added functionality by integrating
web architectures and object service architectures. Specifically, it enables
run-time access to Java, CORBA, and DCOM middleware component libraries
as a source of services to extend the behavior of web applications on the
fly. The implementation of this Java-based architecture is application-independent
and minimally requires the addition of only three classes to be successfully
integrated with any application. Further, the architecture is itself component-based
and very extensible, and can self-assemble from the web on-the-fly as required.
We have used this scalable architecture to extend the functionality of
a web server, a web proxy, Netscape Composer, and Netscape's Mozilla Web
Browser. In these implementations we've used the architecture to enable
application users, developers, and content owners to control the dynamic
insertion of many kinds of functionality. Many of the services we've implemented
include: authorization, change notification, document versioning, file
compression, web page content modification, a network weather service,
and URL request modification. We've also experimented with endowing the
Mozilla browser with a user and content provider controllable dynamic user
interface. Further, as a scalable mechanism to support web objects, the
use of the Interceptor Architecture in our prototypes has enabled users
to associate sets of behaviors (in the form of services) with individual
web resources.
Table of Contents
An Internet Service Architecture (ISAs) [Thompson, et al.] is the class of architectures which attempts to integrate OSAs and the web. As cited above, the reason for pursuing ISAs is to gain the benefits of OSAs in web application development. Two common types of ISAs include server-side CGI scripts which invoke backend ORB-based services, and client-side ORBs which might be embedded in the browser or downloaded via an applet. In both cases, component services are invoked which extend the capabilities of a web application.
For more than two years we have been working on the design and implementation of a new type of ISA which we have classified as an Intermediary Architecture. An Intermediary Architecture [Thompson, et al.] attempts to interpose services between the web client and web server. Using services we can augment the behavior of the interchange. Existing technology, specifically proxies, which manage the communication pipeline between a client and server, could be classified as hardwired intermediaries. In general they have been used to cache data, provide firewall support, as well as statically apply filters to all data that passes through them.
Our implementation of the Intermediary Architecture provides the ability to insert services dynamically at any point within an intra- or inter-application communications stream. The principal initial observations and objectives of this project included:
An alternative to the client-side and server-side ISAs is the Intermediary Architecture. In contrast to these two approaches the Intermediary Architecture facilitates the insertion of middleware services between the client and server, in many ways similar to a proxy server which acts as an intermediary between a web client and web server. This approach allows a process to monitor web events, and conditionally augment the apparent behavior of the web client and web server by invoking object services.
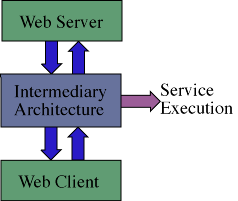
Figure 1. Conceptual Intermediary Architecture
From an implementation standpoint this could be accomplished in one of two ways. First, we could implement the layer external to the application(s) of interest, and effectively filter the incoming and outgoing communications. This, for example, could be accomplished by using a web proxy through which a client and server would communicate. Alternatively, a second implementation approach would be to tie directly into an application, monitor internal communications, and selectively augment the behavior of that application.
The first approach is applicable when the applications are closed, since only the inter-communications can be intercepted and possibly modified. However, the approach is limited because it can only effect change through modification of inter-application communications. On the other hand, the second approach can be used when the application's design exposes suitable hooks from which this external architecture can augment the application's behavior by accessing and modifying intra-application communications (and data structures). If the appropriate hooks, or insertion points, needed to effect the desired changes are not available, it would be necessary (if at all possible) to modify the application's source code to expose such points.
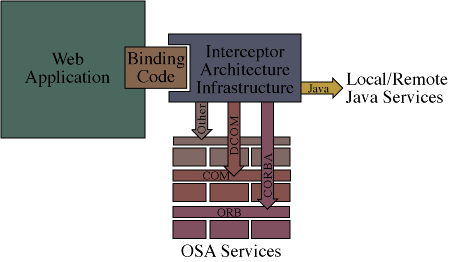
We can implement the second approach, and effectively both approaches, using the second architecture described above. Using binding code, which accesses (some portion of) the application's internals via available hooks or source code modification, interesting events are filtered and passed on to the architecture for processing. The architecture then has the power to augment the application's behavior via the execution of local and remote object services. As this architecture intercepts intra-application communications we call it the Interceptor Architecture.
To invoke the IA the application is extended either through points exposed by the software vendor (e.g. plug-ins), or through points manually exposed via source code modification. The latter may be necessary because the vendor did not want to expose such expansion points (e.g. increases development and support costs, perhaps no customer demand, or didn't want third parties extending their product). It is from one or more of these expansion points, or intercept points, that the IA is invoked. For each invocation some portion of the application's state is passed to the IA for modification by one or more services. Each service may or may not modify this state, and depending upon the application a service could interact with other services, remote servers, or even directly interact with the user (through dialogs it might display). Once the services have completed their execution, the possibly modified state is returned to the application. Therefore, the behavior augmentation which the IA facilitates is the combination of all service executions and application state modifications. The behavior of any application can be significantly changed through such a mechanism. While plug-ins and other mechanisms provide a capability to extend application behavior, there are several important factors which differentiates the IA from them, including:
Figure 2. Interceptor Architecture
The invocation of the IA from the intercept point in the application is tied to the occurrence of "interesting" events -- one or more events can occur at a single intercept point. Therefore, as part of the invocation process, an event object containing (at least) the name of the event is also passed to the IA; the IA then uses this information, in part, to determine which services to invoke. This event corresponds to a specific point in the application, so from the perspective of inserting new behavior we can insert it before or after the event that occurs within the application. This approach is similar to before-after method wrappers supported in some languages, before-after triggers used in DBMSs, around methods used in CLOS, sentries used in the DARPA Open OODB system [Wells et. al. 1992], before-after filters in OMG's Portable Object Adapter specification, server-side filters in web servers like W3C's Jigsaw, etc. Note that while the IA supports before-after methods, this is simply a default as it is possible in the IA to implement other types of behavior augmentation.
Therefore, the IA can then be invoked just before the event (corresponding
to some point in the application) occurs, and just after it. Given adequate
control, it is also possible to invoke services in the IA in lieu
of the event in the application. This enables the behavior of the application
not only to be augmented, but also to be replaced. "Adequate control" is
not provided by all expansion point architectures (it is always implementable
when source code is available), but when provided it either allows code
to be supplied to replace the default application behavior or it simply
allows the default behavior to be turned off. Again, remember that while
mechanisms provided by applications today allow augmentation of application
behavior, they do not provide the significant benefits of the IA infrastructure
as outlined above.
One of the reasons the IA architecture is reusable is due to the fact that the invocation parameters and returned objects associated with the invocation of the IA are packaged up at a high-level as generic Request and Reply objects. The infrastructure marshalls the objects through to each of the services that are executed, and then returns the reply back to the application. As a result, the IA can handle any kind of request or reply as long as they inherit the generic high-level interfaces.
Intercept points can be used wherever one needs to extend application behavior. In a web client one could, for example, use intercept points to modify the user interface of the application, modify the content the downloaded resources, or modify the outgoing request. One could also extend the capabilities of the application by adding new functionality. In a web server, one might extend the behavior of the server before and after resources are accessed (e.g. by adding authorization, change notification, versioning, etc.).
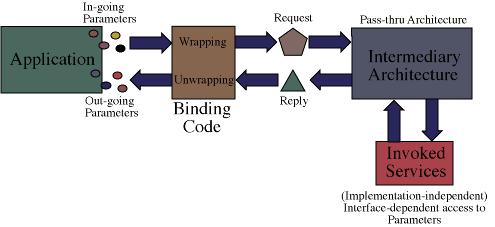
Figure 3. The Role of the Binding Code
The kind of services that can be invoked by the IA may be either local or remote Java classes, or services accessible from any of the OSAs, such as CORBA or DCOM. As part of the definition of a service within a service set (see the example specification), it includes descriptors for the type of service, its remote server/address, and the interface it implements. The interface descriptor is used to ensure that the service implements the proper interface for the application using it. The service type is used to determine how the service must be accessed (e.g. via CORBA/IIOP). Finally, the address of the service is used as a means to locate the service, whether local or remote.
When a service is invoked, say in a web client, it may itself invoke local or remote services, possibly on a web server. This is one way versioning can be supported on a web client, for example. In the client application, whose user interface has now been extended using the IA to include support for server-based versioning, the versioning service invoked by the client may manage the versioning process with a configuration management service placed on the server (which may itself be accessible via an IA-extended web server).
It is important to understand that services executed by the IA will
generally be application or application-class specific. That is, a service
will be written either with a specific application or a class of applications
in mind. Services written for a specific application can only be used by
that application, e.g. the W3C Jigsaw server. Alternatively, services written
for a class of applications, e.g. web servers, can generally be used by
all web servers. There are benefits and drawbacks to both. In the first
case, application-specific services can take advantage of knowledge about
application-specific data structures, but these services cannot be used
by other applications. To implement a more broadly applicable service,
information generally available across the class of applications to be
targeted would be used as a base for defining the service's interface.
This would require understanding the information required by these applications,
and then generating a high level interface to it. Then, when the application's
parameters are passed to the IA during an invocation, they would be wrapped
by an object which implemented this high-level interface. Generic (application-class)
services would access the parameters via this interface, while application-specific
(or application-aware) services could access the lower level details of
the parameters via the application-specific interfaces for those objects.
How the parameters are wrapped is the responsibility of the binding code.
So, in the second case, while services can be reused across a class of
applications, only information which is generally common to all (per the
discretion of the service interface implementor) applications will be accessible.
The difference is really one of standardization of service interfaces versus
proprietary ones.
Another benefit of the IA not possible with current solutions, in addition
to those cited at the start of this section, is that it enables end-users
and developers to easily plug in software components from middleware ORB-based
and other service architectures to extend web applications. This is important
not only because it empowers end-users, but also because it provides a
potential market for the development of widely reusable components, and
because of the ease of which such components can be plugged in.
The current implementation of the IA is the result of two successive
versions. The first version focused on augmenting the resource-specific
behavior of web servers, specifically the Jigsaw web server, with object
service functionality. While it was successful at extending the functionality
of the server and supporting web objects, the implementation of the IA
was tied to Jigsaw. Therefore, the architecture didn't scale and was not
reusable. Because of this, two primary objectives for the second version
included reuse and scalability. To meet these goals we felt that the resulting
architecture had to be extremely extensible to be able to adapt to meet
the needs of most any environment or application.
While the first version was dynamic, in that it could load and execute services at the granularity of an event-object pair, its underlying architecture was not extensible. That is, each of the components of the IA had specific capabilities that could not be changed to adapt to different environments or applications. This severely limited its ability to be reused. What we felt was required was an architecture that would allow component-wise substitution. This would allow new components to be designed and used at anytime without requiring a re-architecting of the IA. This solved the problem of reuse. However, given the diversity of uses of the WWW and kinds of data being accessed, it was important that each implementation of the IA was not tied into a particular configuration thereby constraining what it could actually do. For this reason we made the IA dynamically reconfigurable at the level of an event-object pair. What this meant was that the components of the IA would be assembled on the fly, and more importantly, that different implementations of those components could be used on each invocation.
This approach allowed us to define an infrastructure for augmenting the functionality of any application without tying it to any specific (static) implementation. Furthermore, the components of the IA could themselves be object services retrieved and loaded at runtime from the WWW. Note, too, that reuse was also partially enabled by the use of the high-level Request and Reply wrappers as described earlier.
Most of the primary components and invocation process for the second version of the IA are shown in the following figure (Figure 4).
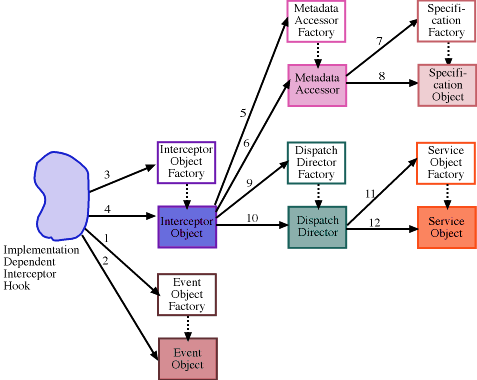
Figure 4. IA Components and High-level Component Interaction
Note that in the graphic above, the even-numbered arrows are pointing to component object types, and perhaps not more appropriately to instances of these types. This is because we are mixing dynamic and type models in one illustration... hopefully this will not be confusing. In addition, this discussion pertains to an abstract implementation, and therefore refers to abstract IA classes when appropriate. Actual implementations, in most cases, may use the default implementations of these classes.
Event Objects (arrows 1/2)
The first step, once (the intercept mechanism's interpretation of) an "event" occurs at the intercept point, is to create an Event Object. An event object is an architecture-consumable representation of some application functionality we want to augment. To create an event object, the binding code must invoke a creation method on the Event Object Factory. This invocation, with supplied parameters, causes the Event Object Factory to return an appropriate (new) instance of an event object subtype to the intercept mechanism. A Basic Event Object simply contains an event identifier, although the structure and behavior could also be much more complex by specializing the Event Object.The extensibility offered by implementing specialized Event Objects is the ability to more accurately model (and handle) application-specific representations of events. The data within these events can then be consumed by other specialized IA components, as well as the services invoked in response to the event.
* The individual object factories depicted above represent a logical implementation. The actual implementation of the factories, is as a single class: com.objs.ia.factory.iaObjectFactory . As with the other IA components, the iaObjectFactory may also be extended.
Interceptor Objects (3/4)
Once an event object has been instantiated the intercept mechanism (which we also call the binding code) requests an Interceptor Object (com.objs.ia.interceptor.InterceptorObject) from its factory. From this point on, the intercept mechanism interfaces with the Interceptor object, while the Interceptor Object interfaces to the Metadata Accessors and Dispatch Directors of the IA. The Interceptor Objects determine how the component interaction takes place, e.g. what metadata is requested from the Metadata Accessor, and when and how the functionality of the Dispatch Directors are invoked. While there will be default objects for each of the components described, new object subtypes can be created (new factories could be created as well, along with services to locate factories, but we do not address this possibility).Once a new Interceptor Object is returned to the intercept mechanism, the intercept mechanism needs to ask the Interceptor Object to process the Event Object. How this actually occurs depends upon the interceptor (and actually on the mechanisms available to intercept the event). Using the basic Interceptor Object (com.objs.ia.interceptor.BRAInterceptorObject, our default implementation), it would be possible to execute services before the event, after the event, and in lieu of, or instead of, the event.
The extensibility offered by implementing interceptor object subtypes provides the ability to control how event augmentation proceeds. It must understand how to interpret and process event objects (for the event object subtypes it accepts). It however does not need to understand the format of the metadata, or service specifications.
MetadataAccessor Objects (5/6)
Once the Interceptor Object has been invoked it requests a new Metadata Accessor Object (com.objs.ia.accessor.MetadataAccessor) from the corresponding Factory so that it can retrieve the appropriate service specifications. The Metadata Accessor Object returned must be aware of where the specifications are stored, or how to look for them (for the given object). It does NOT need to understand the format the specifications are in. This requires that the Interceptor Object knows what to ask for from the Metadata Accessor factory, as well as how to configure the new Metadata Accessor object. The interceptor binding code defines the type of Metadata Accessor to instantiate based upon its knowledge of where the service specifications are stored. For example, if the specifications are stored in local files (e.g. perhaps where there is a specification file per web resource), then the FileMetadataAccessor (com.objs.ia.accessor.FileMetadataAccessor) would be used. If the specifications were accessible via URLs, then the URLMetadataAccessor would be used (com.objs.ia.accessor.URLMetadataAccessor). Other specializations of MetadataAccessor could be implemented as well.Once the new Metadata Accessor has been returned from the factory and configured through initialization, the Interceptor Object can request a Service Specification Manager which is responsible for retrieving the specific service specifications for the event to be augmented. The Metadata Accessor returns an appropriate Service Specification Manager Object capable of understanding the structure and language of the service specification.
The extensibility offered by implementing Metadata Accessors includes flexibility in defining how the metadata is stored and retrieved (e.g. separate files, a DBMS, etc.).
Specification Objects (7/8)
As described above, upon request the Metadata Accessor returns a service Specification Manager Object (com.objs.ia.specification.SpecificationManager) to the interceptor, which it in turn uses to retrieve the specifications and then passes them off to a Dispatch Director to execute. The service specifications are grouped by phase, so that the Dispatch Director will ask for the before, replacement, or after set of service specifications to execute. The Specification Manager Object reads in the service specifications and instantiates Specification Objects (aka Generic Service Objects) -- one per service, which are object representations of the services described in a specification. The format of the Specification Objects returned by the Specification Manager is determined by the metadata specification itself -- either the Metadata Accessor determines the Specification Object type from what it knows or can derive from the specification, or an attribute value in the specification itself indicates what kind of Specification Object should be used (one kind of Specification Object is used for all services contained within a single specification). In both cases, the Metadata Accessor requests the appropriate Specification Manager Object from its factory which understands how to convert service specifications into IA service Specification Objects (instantiated as com.objs.ia.specification.GenericServiceObject objects).Consider Specification Objects as high-level service wrappers. They will wrap services of any type. For instance as a default type, the GenericServiceObject type is used to wrap services whether they are Java, CORBA, or DCOM-based. This provides a layer of insulation between the instantiation and execution of services. Service execution is handled by the Service Objects.
The extensibility offered by implementing Service Specification Manager Object subtypes is that it enables more complex service Specification Objects to be defined (the basic specifications are structured as a simple list of services to be executed). For example, extending this object type would be one step that is required if ECA-related condition statements or scripts were to be embedded within specifications. In addition, it enables multiple specification formats to be supported (e.g. HTML, IDL, XML, etc.), what specification and service object subtypes will be used to represent these specifications as services, and what other kinds of metadata it will return.
The definition of a Specification Manager Object type directly affects the capabilities of the Dispatch Director to interpret and execute specifications.
DispatchDirector Objects (9/10)
Once the Interceptor Object has initialized the Specification Manager Object, it must pass it to a DispatchDirector (com.objs.ia.dispatch.DispatchDirector) for processing. How the specification is executed is controlled by the Dispatch Director, so the Interceptor Object must request an appropriate Dispatch Director from its factory (the DispatchDirector Factory). Each set of specifications for a target will specify what kind of Dispatch Director is required to execute the specification -- the Interceptor Object uses this information when requesting a new Dispatch Director from its factory. Once the new Dispatch Director is invoked, it retrieves the appropriate portion (by phase) of the specification from the Specification Manager, and executes the services contained within that set of specification objects. This execution process is guided by the design of the director, so variations are possible. The basic or default behavior is to execute the default service specification object (simply a list of the services) sequentially.The extensibility offered by implementing DispatchDirectors is primarily over how specifications (and the services within) are executed. While the default behavior was described above, significant enhancements could be added (as with the other components). For example, the default behavior of the IA could be interpreted as implementing the event-condition-action (ECA) profiles of EC-x-A, or E-x-CA. Using the three potential places for any of these to occur (application-dispatcher-service), the EC-x-A profile corresponds to event detection (E) and condition checking (C) occurring in the application, nothing (x) occurring in the dispatcher, while action execution (A) would occur in the service. An EC-x-A profile applies when it is solely the application's responsibility to determine when a service is executed. However, in general, it will be up to the service itself (which corresponds to an E-x-CA profile). For the E-x-CA profile, E occurs in the application, nothing (x) in the dispatcher, and CA occurs in the service (so the service performs condition checks to see if it should perform the associated action). However, by extending the specification language to support conditional statements, the profile could become E-C-A; this moves condition checking (C) to the dispatcher, which is an optimization, as the service is not executed unless the conditions are met. In reality, condition checking of some sort is occurring in both the application and the service (EC-x-CA). By enabling the dispacher to perform some types of condition checking to reduce service invocations when they are unnecessary we gain a better optimized execution (the resulting profile would be EC-C-CA). However, more importantly, other event models could also be supported via this extensibility.
In general, there must be some agreement between the binding code, Interceptor Objects, and Dispatch Directors regarding how an event is processed and specification is executed. Thus, specification structure is not independent of the Dispatch Director used.
Service Objects (11/12)
The Service Specification Manager Object passed to the Dispatch Director provides access to the services to invoke them. By default each Specification Object (instantiated as a com.objs.ia.specification.GenericServiceObject, or a specialization of this), contained within the specification will indicate its implementation type. Using this information, the Dispatch Director will request a type-specific Service Object (com.objs.ia.services.ServiceObject) from the Service Object Factory. This new instance of a Service Object subtype will understand how to execute the service described by the instance of Generic Service Object. This enables services of any kind to be defined and invoked, whether local or remote, since the actual implementation of the service is encapsulated by the service object (which can be actually viewed as a service wrapper). We could, for example, implement services in Java, in C++, in LISP; or use distributed programming architectures such as CORBA, DCOM, or ActiveX. The second version of the IA supports local and remote services written in both Java and CORBA. (The implementation type in the default case would be either "Java" or "CORBA".)While the example below shows what a sample service specification looks like, the format of a specification can be significantly more complex. This is controlled by the Specification Manager Objects (which read them), the Service Specification Objects (which contain them), the DispatchDirectors (which must understand how to execute them), and the Service Objects (which must understand how to execute each service specified in the language).
The extensibility offered by implementing Service Object subtypes is specifically the ability to incorporate and use services implemented in any way possible since their implementations can be encapsulated within these Service Objects. This, in turn, enables dynamic extensibility of the environment this architecture has been tied into because the environment need not be aware of the implementation of the services prior to their execution.
The various prototypes were identified with the intent to test the broad applicability and generic design of the architecture. The different implementations have allowed us to understand the requirements of a spectrum of application types, and in turn, appreciate the flexibility, scalability, and reusability of the IA architecture.
Two of the services we implemented for this prototype included a network weather service which recorded the time it took to download web resources from various servers, and an annotation service which merged annotations about a given resource with the page before it was returned to the client. From the perspective of the client, the proxy is the server, and from the server's perspective the proxy is the client. For this reason, the proxy is a suitable place to logically extend the behavior of either one from the view of the other. For example, client-side proxy services could insert user-defined HTML-based menus or applets into all (or a selected set of) downloaded web pages, filter content, manage web navigation histories, submission of IDs and passwords, etc. Examples of services modifying outgoing requests include those that expand or alter URL addresses per some configuration preferences, modify web queries, or submit queries to multiple sites automatically. Keep in mind that many of these services could be executed on the server, in a proxy, or even in a client browser. We view this choice as an optimization when applicable.
As a client-side proxy, the user has control over what services are inserted (via the definition of a specification), and when. As a server-side proxy, the proxy administrator would have control. However, if so configured, any resource having a specification which contained proxy-intended services could also dictate which services to execute (the proxy could inquire about the existence of any specifications when accessing the resource).
Other services we implemented for this prototype included authorization,
security-based content filtering, versioning, compression, and change notification.
Each of these services could be used in any combination (or none at all)
as specified by the content owner by associating a specification with a
given resource. Within the specification, the services could be further
customized by supplying parameters, or links to parameter files. For example,
for authorization the owner can specify who can access the page, and what
the usernames and passwords are. Content filtering allows portions of a
document to be extracted prior to sending off to a client based upon the
access permissions of the client. So, for example, a client with no clearance
would see the minimal document with confidential and secret information
removed, while a secret-cleared client would see the entire contents of
the document. The versioning service allows customizable versioning to
be supported, including maintenance of version trees (this service is actually
tied to a client-side version service we wrote for client editors). Change
notification allows the resource owner to be notified whenever their document
is checked back into the server. Of course, this is only a representative
sample of the kinds of services which could be implemented.
First, we defined binding code which intercepted URL requests in the browser (in C++) and sent them off to the IA (via a Win95 DLL which used JNI to call Java). The IA, via a specification, simply redirected specific URLs to other sites. It could as well have checked the user's authorization for those pages. We then implemented a second intercept point which allowed us to modify the content of the returned pages (as dictated in a specification), e.g. so we could use an annotation service.
Finally, we modified Mozilla to support a dynamic user interface. The idea behind this extension was to allow users, and web objects (resources + specifications) loaded by Mozilla, to add new toolbars and buttons to the associated window which were necessary or useful when dealing with the content of a given object. While much of this demonstration required a significant amount of time to implement, more than 95% of the effort was spent in extending Mozilla -- no modifications to the IA were required, only additions to handle the specific user interface augmentation services. Simply put, when a given resource was loaded, if it contained a reference to any window widgets those widgets would be converted from an XML-based definition directly to window widgets/objects in C++.
A short time after we began the design of this prototype, in our semi-constant
talks with Mozilla user interface engineers (who we graciously thank for
their support!), we were told that Mozilla was planning to implement some
form of configurable interfaces themselves. However they made it clear
that their goal was to provide a statically user-configurable interface,
so we could see that there would be no way for content owners (via web
objects) to alter the user interface -- dynamically or otherwise. However,
their extension does provide an important component of our overall solution.
That is, while we could alter the user interface, we desired a scripting
capability to associate menu choices with scripts and browser commands.
The configurable menus extension will supposedly add this feature.
Interoperability is an important factor for any widely used system. In the case of the IA, two interoperability issues involve service APIs and specification formats. Interoperability of services is enabled by adopting shared service APIs for classes of applications. So, for example, all web servers, or web browsers, would each define sets of APIs for different binding points. Of course, while this is not necessary it would enable services to be used across classes of applications. In fact, any of the plug-ins that are compatible across Microsoft's Internet Explorer and Netscape's Communicator are components that are already available. Just as in a prototype (not described above) where we have extended Communicator's Composer to insert new plug-ins or switch plug-ins (services) on the fly, we could do the same to Explorer or Communicator.
Specification format is another interoperability issue, but more so at the level of specification creation. In general, a specification format needs to be standardized for a specification composition application to use it. However, given the extensibility of the IA itself, as long as an IA-compatible specification manager component has been defined to read the format used, any specification format can be used by the IA. [Recall that the IA will load in, locally or remotely, a manager whose job it is to convert a specification into IA-compatible specification objects. The default manager recognizes a specific format written in XML.]
Another important issue is the availability of binding points within
web applications. While applications have provided some basic capability
to install new functionality, the benefits of the IA will be realized more
significantly as web application developers provide architectures which
are increasingly open to extension. From our experience, the amount
of effort required to expose this openness to use the IA is not significant
given the benefits.
Regarding accessibility, as described previously this architecture
facilitates dynamic customization of web content by content author as well
as customization of the web browser by the end-user. While the web
browser vendors cannot provide functionality to aid viewing for every disability,
they could provide hooks to key points within their programs. These access
points could then be used in conjunction with the IA to enable customizable
insertion of disability-specific services, such as talking buttons, verbal
and textual descriptions of the page layout, or embedded pictures could
be retrieved and described. Further, content structure according to W3C's
document layout could be used as a means to navigate the document using
verbal commands. In our Mozilla prototype we demonstrated such a capability
by enabling service specifications to dynamically alter the user interface
on a resource-by-resource basis via the insertion of services.
[CORBA] The Object Management Group, http://www.omg.org
[DCOM] Microsoft Corporation, DCOM Technical Overview, http://www.microsoft.com/windows/downloads/bin/nts/dcomtec.exe
[HTTP-NG] World Wide Web Consortium (W3C) HTTP Next Generation, http://www.w3.org/Protocols/HTTP-NG/
[IBM] McFall, C., "An Object Infrastructure For Internet Middleware: IBM on Component Broker," IEEE Internet Computing, Vol 2 No. 2, March/April 1998.
[Jigsaw] World Wide Web Consortium (W3C) Jigsaw Server, http://www.w3.org/Jigsaw/
[JavaServer] Javasoft, Java Web Server Developer Documentation, http://jserv.java.sun.com/products/java-server/documentation/webserver1.1/index_developer.html
[JNI] Gordon, R., "Essential JNI," Prentice Hall, 1998.
[Manola] Frank Manola, "Technologies for a Web Object Model", to appear as lead article in the Special Issue on Web Object Models, IEEE Internet Computing, Jan/Feb 1999.
[Mozilla] The Mozilla Browser. Information and documentation is available at http://www.mozilla.org.
[PEP] World Wide Web Consortium (W3C), PEP: An Extension Mechanism for HTTP, a W3C Working Draft, http://www.w3.org/TR/WD-http-pep-970321, 1997.
[PICS] World Wide Web Consortium (W3C) Platform for Internet Content Selection (PICS), http://www.w3.org/PICS/
[Thompson, et al.] Thompson, C., P. Pazandak, V. Vasudevan, F. Manola, M. Palmer, G. Hansen, T. Bannon, "Intermediary Architecture: Interposing Middleware Services between Web Client and Server", OBJS DARPA Contract DAAL01-95-C-0112 Project Report, http://www.objs.com/OSA/Intermediary-Architecture.html, 1998.
[Vasudevan 1998a] Venu Vasudevan, "A Reference Model for Trader-Based Distributed Systems Architectures," OBJS Technical Report, 1998, URL: http://www.objs.com/staging/trader-rm.html.
[Vasudevan 1998b] Vasudevan, V. and M. Palmer. "Web annotation: promises and pitfalls of Web infrastructure", 32nd Hawaii International Conference on Systems Sciences (January 1999)
[Wells et. al. 1992] David Wells, Jose Blakeley, Craig Thompson. "Architecture of an Open Object-Oriented Database Management System." IEEE Computer, October 1992.
[XML] World Wide Web Consortium (W3C) Extensible Markup
Language (XML), http://www.w3.org/XML/
Specifications - In general, a specification can be associated with anything, not just a resource. For example, we could associate specifications with different users so that an application would exhibit user-specific behavior. Or, specifications could be associated with different times of the day, the language of the user, or any disability-based information that was accessible.
This particular format of specification written in XML is understood by the XML Specification Manager (com.objs.ia.specification.xml.XMLSpecificationManager). Each specification includes a set of parameters that are required to locate and invoke the service. The Params element includes a set of service-specific configuration parameters which are passed directly to the service upon invocation.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE iaspec PUBLIC "-//OBJS//DTD IASpecification//EN" "IASpec.dtd">
<IASpecification dispatchertype="BRA">
<ServiceSet phase="BEFORE"
event="GET">
<Service
servicename="Internet Weather Service"
serviceid ="com.objs.ia.Weather.weather"
servicetype="JAVA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
hasInterface="false"
doInit="true"
serviceOrder="2"
>
<Params mdr="http://www.objs.com/weather/MDR:8017"
stats="ALL"/>
</Service>
<Service
servicename="Basic Public-Private Routing Service"
servicedoc="http://www.objs.com/service/router/doc.html"
serviceid ="com.objs.ia.router"
servicetype="CORBA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
remoteSOHandler=""
remoteSHCodebase=""
codebase="http://www.objs.com/CORBAServer:8011"
hasInterface="false"
doInit="false"
serviceOrder="1"
>
<Params public="/Public" private="/Conf" privFilter="*.objs.com"
pubFilter="*.edu|*.gov" other="/Sorry.html"
servicedata="http://www.objs.com/service/router/initdata.xml"
servicedatatype="XML"/>
</Service>
</ServiceSet>
<ServiceSet phase="AFTER" event="GET">
<Service
servicename="Internet Weather Service"
serviceid ="com.objs.ia.Weather.weather"
servicetype="JAVA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
hasInterface="false"
doInit="false"
serviceOrder="1"
>
<Params mdr="http://www.objs.com/weather/MDR:8017"
stats="ALL"/>
</Service>
</ServiceSet>
<ServiceSet phase="AFTER" event="PUT">
<Service
servicename="Change Notification"
serviceid ="com.objs.ia.services.ChangeNotification"
servicetype="JAVA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
hasInterface="false"
doInit="false"
serviceOrder="1"
>
<Params notify="pazandak@objs.com"/>
</Service>
</ServiceSet>
</IASpecification>
© Copyright 1997, 1998, 1999 Object Services and Consulting, Inc. Permission is granted to copy this document provided this copyright statement is retained in all copies. Disclaimer: OBJS does not warrant the accuracy or completeness of the information in this paper.