As an alternative we have explored the use of distributed object component
architectures (e.g. CORBA, DCOM, etc.) as an avenue to provide extensibility
to the WWW so we could better understand how such distributed architectures
scale to the internet. This document presents an overview of the implementation
of an infrastructure which facilitates this goal.
The principal objectives of this project included:
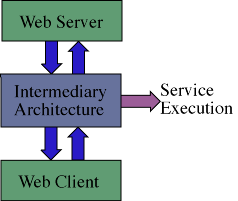
From an implementation standpoint this could be accomplished in one of two ways. First, we could implement the layer external to the application(s) of interest, and effectively filter the incoming and outgoing communications. This, for example, could be accomplished by using a web proxy through which a client and server would communicate. Alternatively, a second implementation approach would be to tie directly into an application, monitor internal communications, and selectively augment the behavior of that application.
The first approach is necessary when the applications are closed, since only the inter-communications can be intercepted and possibly modified. However, the approach is limited because it can only effect change through modification of inter-application communications. On the other hand, the second approach can be used when the application's design exposes suitable hooks from which this external architecture can augment the application's behavior by accessing and modifying intra-application communications (and data structures). If the appropriate hooks, or insertion points, needed to effect the desired changes are not available, it might be necessary (if at all possible) to modify the application's source code to expose such points.
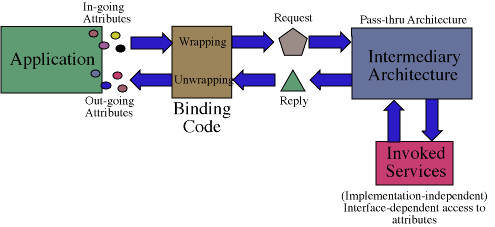
We can effectively implement both approaches using the second architecture
described above and illustrated in Figure 2 below. Using binding code,
which accesses (some portion of) the application's internals via available
hooks or source modification, interesting events are filtered and passed
on to the Intermediary Architecture for processing and possible
behavior augmentation via the execution of local and remote object services.
Granularity of Augmentation
Once the insertion point has been identified (some applications could
conceivably have a number of insertion points) and binding code implemented,
the next issue to address is when to augment the behavior of the
application. Say, for example, that the application is a web server and
that we would like to insert an HTML-based menu on each page returned.
Then, we would insert this service-provided functionality (which modifies
a page before returning it to the client) every time an HTTP GET occurs.
The granularity of augmentation is then set coarsely at the level of a
GET event.
Alternatively, we may decide that we want to retrieve and insert annotations applicable to some subset of pages (internal scientific reports). While this behavior augmentation is still applicable to HTTP GET events, the granularity has become finer -- to that of a single page.
In fact, any level of granularity can be supported within the IA. What is required is that a service specification exists which describes what services should be invoked for a given event (and target). In the first example, since all pages were to be modified when a GET event occurred, a specification need only identify the services and associate them with the event GET. In the second example, a specification would not only have to list the services, but also the targets (or in this example, specific web resources) to which they should be applied. Therefore, in general, a specification must include three things: an event, a (possibly null) target, and a set of services to execute.
Note that a target object can be anything: a single web page or file, a client's IP address or name, the time of day, etc. The target can be simple, or it can be complex (e.g. time and a file). The target could also be derived from a conditional statement. Given this event-target information pair, the IA will retrieve the appropriate specification if it exists, and execute the defined services. Since service execution is tied to the occurrence of events, we call this event-based behavior augmentation. The use of targets then enables us to control the granularity at which the augmentation occurs.
Service Specifications
We have mentioned the need for service specifications which define
what services to execute. Further, we tie these services to an event-target
pair. The format of a specification is not constrained as components of
the IA can be specialized to handle any format. As such, there must be
some means to determine the format of the specification so that the proper
component specialization (called a Specification Manager) can be
loaded to access it. For example, the format may be stored in a database,
or embedded within the specification itself; it may be written in XML or
IDL, etc.
Service Execution
Given that the specification format is unrestricted, it is also necessary
to identify which specialization of IA component will direct the execution
of the services defined within the specification (the class of component
in charge of service execution is called the Dispatch Director)
. Before addressing this in greater detail we need to discuss the kinds
of behavior augmentation that might be supported.
First, what constitutes an event can be defined by the application or the binding code, there is no rigid definition. We could decide that whenever x=6 we will define that as an event. Or when any HTTP method invocation (GET, PUT, POST, etc.) is received from a client could be defined as an event. Next, we need to identify when we can execute services to augment the behavior of the application in response to this event. It may be possible to capture the event and execute services before the application performs its normal action in response to the event; or, after the normal action; or, perhaps it may be possible to deactivate the application's normal action, and perform a replacement action. The LISP language has a concept similar to this called around methods. We call the temporal points (in relationship to the occurrence of an event) at which services can be inserted the phases of augmentation.
Again referring to a web server example involving a client-submitted GET event where the target is a file resource, a before action phase might invoke a service which alters the URL to redirect the request for server load-leveling; an after action phase service might insert an HTML-based menu or pertinent annotations into the file to be returned to the client; and, a replacement action phase service might dynamically generate the content of the page from a database.
So, depending upon the architecture of the application, its openness, the programming language used, etc., some or all of these phases may be supportable. Therefore, in addition to specifying the services for an event-target pair, we need to identify in which phase the services should be executed. So, the set of services to be executed is then associated with an event-target-phase triplet. A sample service specification in XML is here.
When a service is invoked, at a high-level the application state is passed into the services via request and reply objects. For before-phase services, a request object is passed in, and returned (services can only modify the request); for replacement-phase services, a request object is passed in, and a reply object is returned (services must return a non-null reply object); and, for after-phase services, a reply is passed in, and a reply object is returned (services can only modify the reply). This high-level di-parametric approach frees the IA core architecture from implementation details and is one reason that the implementation is reusable.
However, to write a generally useful service, access to application state will be required. Therefore, once a service is passed in the request and/or reply objects, they are cast to context-specific object types so that more of their content is exposed. This context/API can be generic enough so that different applications of a given kind (e.g. all web servers) can share services (see interoperability issues for a more detailed discussion). However, a service could as well cast the objects to application-specific types and expose application-dependent structures. Yet it is important to understand that the context-specific types provide a means to hide or wrap implementation details so that services can interoperate between IA implementations.
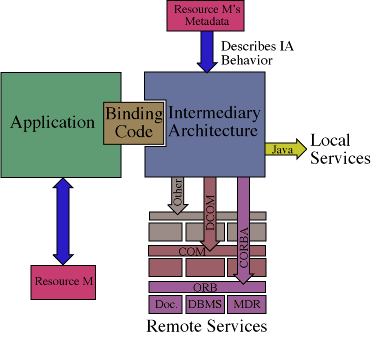
While the IA has a demonstrated ability to insert object service technology into WWW applications, it may actually be used to augment the behavior of many kinds of applications.
While the first version was dynamic, in that it could load and execute services at the granularity of an event-target pair, its underlying architecture was not extensible. That is, each of the components of the IA had specific capabilities that could not be changed to adapt to different environments or applications. This severely limited its ability to be reused. What we felt was required was an architecture that would allow component-wise substitution. This would allow new components to be designed and used at anytime without requiring a re-architecting of the IA. This solved the problem of reuse. However, given the diversity of uses of the WWW and kinds of data being accessed, it was important that each implementation of the IA was not tied into a particular configuration thereby constraining what it could actually do. For this reason we made the IA dynamically reconfigurable at the level of an event-target pair. What this meant was that the components of the IA would be assembled on the fly, and more importantly, that different implementations of those components could be used on each invocation.
This approach allowed us to define an infrastructure for augmenting the functionality of any application without tying it to any specific (static) implementation. Furthermore, the components of the IA could themselves be object services retrieved and loaded at runtime from the WWW. Note, too, that reuse was also partially enabled by the use of the di-parametric approach as described above.
In the second version of the IA, the primary components and invocation
process are shown in the following figure (Figure 3).
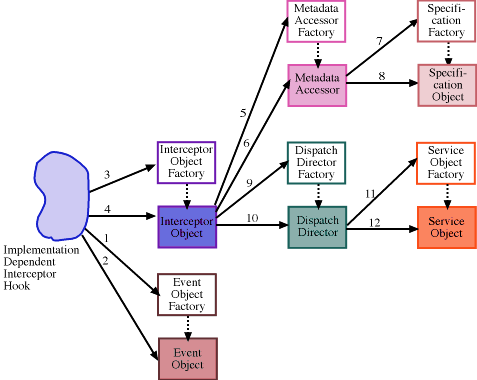
Note that in the graphic above, the even-numbered arrows are pointing to component object types, and perhaps not more appropriately to instances of these types. This is because we are mixing dynamic and type models in one illustration... hopefully this will not be confusing. In addition, this discussion pertains to an abstract implementation, and therefore refers to abstract IA classes when appropriate. Actual implementations, in most cases, may use the default implementations of these classes which are provided in the distribution.
Event Objects (arrows 1/2)
The first step, once (the intercept mechanism's interpretation of) an "event" occurs at the intercept point, is to create an Event Object. An event object is an architecture-consumable representation of some application functionality we want to augment. To create an event object, the binding code must invoke a creation method on the Event Object Factory. This invocation, with supplied parameters, causes the Event Object Factory to return an appropriate (new) instance of an event object subtype to the intercept mechanism. A Basic Event Object simply contains an event identifier, although the structure and behavior could also be much more complex by specializing the Event Object.The extensibility offered by implementing specialized Event Objects is the ability to more accurately model (and handle) application-specific representations of events. The data within these events can then be consumed by other specialized IA components, as well as the services invoked in response to the event.
* The individual object factories depicted above represent a logical implementation. The actual implementation of the factories, is as a single class: com.objs.ia.factory.iaObjectFactory . As with the other IA components, the iaObjectFactory may also be extended.
Interceptor Objects (3/4)
Once an event object has been instantiated the intercept mechanism (which we also call the binding code) requests an Interceptor Object (com.objs.ia.interceptor.InterceptorObject) from its factory. From this point on, the intercept mechanism interfaces with the Interceptor object, while the Interceptor Object interfaces to the Metadata Accessors and Dispatch Directors of the IA. The Interceptor Objects determine how the component interaction takes place, e.g. what metadata is requested from the Metadata Accessor, and when and how the functionality of the Dispatch Directors are invoked. While there will be default objects for each of the components described, new object subtypes can be created (new factories could be created as well, along with services to locate factories, but we do not address this possibility).Once a new Interceptor Object is returned to the intercept mechanism, the intercept mechanism needs to ask the Interceptor Object to process the Event Object. How this actually occurs depends upon the interceptor (and actually on the mechanisms available to intercept the event). Using the basic Interceptor Object (com.objs.ia.interceptor.BRAInterceptorObject, our default implementation), it would be possible to execute services before the event, after the event, and in lieu of or instead of the event.
The demonstration code we have included in this distribution uses this class. In one demo, the binding code that instantiates and interacts with the Interceptor Object is com.objs.ia.JigsawServerInterceptPt.java. It binds the IA to the Jigsaw Web Server. This class, and the specializations of the Request and Reply objects (com.objs.ia.request.JigsawRequest and com.objs.ia.reply.JigsawReply) are all that is necessary to create, and the only classes which are Jigsaw-specific.
The extensibility offered by implementing interceptor object subtypes provides the ability to control how event augmentation proceeds. It must understand how to interpret and process event objects (for the event object subtypes it accepts). It however does not need to understand the format of the metadata, or service specifications.
MetadataAccessor Objects (5/6)
Once the Interceptor Object has been invoked it requests a new Metadata Accessor Object (com.objs.ia.accessor.MetadataAccessor) from the corresponding Factory so that it can retrieve the appropriate service specifications. The Metadata Accessor Object returned must be aware of where the specifications are stored, or how to look for them (for the given object). It does NOT need to understand the format the specifications are in. This requires that the Interceptor Object knows what to ask for from the Metadata Accessor factory, as well as how to configure the new Metadata Accessor object. The interceptor binding code defines the type of Metadata Accessor to instantiate based upon its knowledge of where the service specifications are stored. For example, if the specifications are stored in local files (e.g. perhaps where there is a specification file per web resource), then the FileMetadataAccessor (com.objs.ia.accessor.FileMetadataAccessor) would be used. If the specifications were accessible via URLs, then the URLMetadataAccessor would be used (com.objs.ia.accessor.URLMetadataAccessor). Other specializations of MetadataAccessor could be implemented as well.Once the new Metadata Accessor has been returned from the factory and configured through initialization, the Interceptor Object can request a Service Specification Manager which is responsible for retrieving the specific service specifications for the event to be augmented. The Metadata Accessor returns an appropriate Service Specification Manager Object capable of understanding the structure and language of the service specification.
The extensibility offered by implementing Metadata Accessors includes flexibility in defining how the metadata is stored and retrieved (e.g. separate files, a DBMS, etc.).
Specification Objects (7/8) (now called Specification Manager Objects)
As described above, upon request the Metadata Accessor returns a service Specification Manager Object (com.objs.ia.specification.SpecificationManager) to the interceptor, which it in turn uses to retrieve the specifications and then passes them off to a Dispatch Director to execute. The service specifications are grouped by phase, so that the Dispatch Director will ask for the before, replacement, or after set of service specifications to execute. The Specification Manager Object reads in the service specifications and instantiates Specification Objects (aka Generic Service Objects) -- one per service, which are object representations of the services described in a specification. The format of the Specification Objects returned by the Specification Manager is determined by the metadata specification itself -- either the Metadata Accessor determines the Specification Object type from what it knows or can derive from the specification, or an attribute value in the specification itself indicates what kind of Specification Object should be used (one kind of Specification Object is used for all services contained within a single specification). In both cases, the Metadata Accessor requests the appropriate Specification Manager Object from its factory which understands how to convert service specifications into IA service Specification Objects (instantiated as com.objs.ia.specification.GenericServiceObject objects).Consider Specification Objects as high-level service wrappers. They will wrap services of any type. For instance in this distribution, the GenericServiceObject type is used to wrap services whether they are Java, CORBA, or DCOM-based. This provides a layer of insulation between the instantiation and execution of services. Service execution is handled by the Service Objects.
The extensibility offered by implementing Service Specification Manager Object subtypes is that it enables more complex service Specification Objects to be defined (the basic specifications are structured as a simple list of services to be executed). For example, extending this object type would be one step that is required if ECA-related condition statements or scripts were to be embedded within specifications. In addition, it enables multiple specification formats to be supported (e.g. HTML, IDL, XML, etc.), what specification and service object subtypes will be used to represent these specifications as services, and what other kinds of metadata it will return.
The definition of a Specification Manager Object type directly affects the capabilities of the Dispatch Director to interpret and execute specifications.
DispatchDirector Objects (9/10)
Once the Interceptor Object has initialized the Specification Manager Object, it must pass it to a DispatchDirector (com.objs.ia.dispatch.DispatchDirector) for processing. How the specification is executed is controlled by the Dispatch Director, so the Interceptor Object must request an appropriate Dispatch Director from its factory (the DispatchDirector Factory). Each set of specifications for a target will specify what kind of Dispatch Director is required to execute the specification -- the Interceptor Object uses this information when requesting a new Dispatch Director from its factory. Once the new Dispatch Director is invoked, it retrieves the appropriate portion (by phase) of the specification from the Specification Manager, and executes the services contained within that set of specification objects. This execution process is guided by the design of the director, so variations are possible. The basic or default behavior is to execute the default service specification object (simply a list of the services) sequentially (see com.objs.ia.dispatch.BRADispatchDirector).The extensibility offered by implementing DispatchDirectors is primarily over how specifications (and the services within) are executed. While the default behavior was described above, significant enhancements could be added (as with the other components). For example, the default behavior of the IA could be interpreted as implementing the event-condition-action (ECA) profiles of EC-x-A, or E-x-CA. Using the three potential places for any of these to occur (application-dispatcher-service), the EC-x-A profile corresponds to event detection (E) and condition checking (C) occurring in the application, nothing occurring in the dispatcher, while action execution (A) would occur in the service. An EC-x-A profile applies when it is solely the application's responsibility to determine when a service is executed. However, in general, it will be up to the service itself (which corresponds to an E-x-CA profile). For the E-x-CA profile, E occurs in the application, nothing in the dispatcher, and CA occurs in the service (so the service performs condition checks to see if it should perform the associated action). However, by extending the specification language to support conditional statements, the profile could become E-C-A; this moves condition checking (C) to the dispatcher, which is an optimization, as the service is not executed unless the conditions are met. In reality, condition checking of some sort is occurring in both the application and the service (EC-x-CA). By enabling the dispacher to perform some types of condition checking to reduce service invocations when they are unnecessary we gain a better optimized execution (the resulting profile would be EC-C-CA). However, more importantly, other event models could also be supported via this extensibility.
In general, there must be some agreement between the binding code, Interceptor Objects, and Dispatch Directors regarding how an event is processed and specification is executed. Thus, specification structure is not independent of the Dispatch Director used.
Service Objects (11/12)
The Service Specification Manager Object passed to the Dispatch Director provides access to the services to invoke them. By default each Specification Object (instantiated as a com.objs.ia.specification.GenericServiceObject, or a specialization of this), contained within the specification will indicate its implementation type. Using this information, the Dispatch Director will request a type-specific Service Object (com.objs.ia.services.ServiceObject) from the Service Object Factory. This new instance of a Service Object subtype will understand how to execute the service described by the instance of Generic Service Object. This enables services of any kind to be defined and invoked, whether local or remote, since the actual implementation of the service is encapsulated by the service object (which can be actually viewed as a service wrapper). We could, for example, implement services in Java, in C++, in LISP; or use distributed programming architectures such as CORBA, DCOM, or ActiveX. The version of the IA in this distribution supports local and remote services written in both Java and CORBA. (The implementation type in the default case would be either "Java" or "CORBA".)While the example below shows what a sample service specification looks like, the format of a specification can be significantly more complex. This is controlled by the Specification Manager Objects (which read them), the Service Specification Objects (which contain them), the DispatchDirectors (which must understand how to execute them), and the Service Objects (which must understand how to execute each service specified in the language).
The extensibility offered by implementing Service Object subtypes is specifically the ability to incorporate and use services implemented in any way possible since their implementations can be encapsulated within these Service Objects. This, in turn, enables dynamic extensibility of the environment this architecture has been tied into because the environment need not be aware of the implementation of the services prior to their execution.
This level of interoperability requires uniform treatment of the following items:
Define standard augmentation phases, e.g. before,
replace, and after, which all specifications must abide by (for a given
set of implementations which require interoperability).
This mandates either the consistent use of event
identifiers, or some mechanism which will be able to map identifiers from
one system to another.
Again, this argues for standardizing the set of,
and structure of, the parameters passed to a service.
When a service accesses a Request or Reply Object, it can choose to access the object through the cross-implementation API to maintain interoperability; or, it may decide to access the object through the implementation-specific API of the object. This flexibility allows interoperability (perhaps with a loss of access to some implementation-specific information), but does not restrict a service from accessing the object via an implementation-specific API (perhaps, but not necessarily, with a loss of interoperability).
The figure below shows how application/implementation-specific objects are wrapped by the binding code, then passed generically through the IA infrastructure to the services themselves. The services then cast the objects as implementation-independent, but access point specific objects (e.g. com.objs.ia.request.HttpRequest objects -- applicable to any IA implementation that might use this request object type). At this point, they can request the application-specific object which is being wrapped by the request object (e.g. com.objs.ia.request.JigsawRequest) if the service wants to access implementation-specific details not available through the higher-level API.
This particular format of specification written in XML is understood by the XML Specification Manager (com.objs.ia.specification.xml.XMLSpecificationManager). Each specification includes a set of parameters that are required to locate and invoke the service. The Params element includes a set of service-specific configuration parameters which are passed directly to the service upon invocation.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE iaspec PUBLIC "-//OBJS//DTD IASpecification//EN" "IASpec.dtd">
<IASpecification dispatchertype="BRA">
<ServiceSet phase="BEFORE"
event="GET">
<Service
servicename="Internet Weather Service"
serviceid ="com.objs.ia.Weather.weather"
servicetype="JAVA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
hasInterface="false"
doInit="true"
serviceOrder="2"
>
<Params mdr="http://www.objs.com/weather/MDR:8017"
stats="ALL"/>
</Service>
<Service
servicename="Basic Public-Private Routing Service"
servicedoc="http://www.objs.com/service/router/doc.html"
serviceid ="com.objs.ia.router"
servicetype="CORBA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
remoteSOHandler=""
remoteSHCodebase=""
codebase="http://www.objs.com/CORBAServer:8011"
hasInterface="false"
doInit="false"
serviceOrder="1"
>
<Params public="/Public" private="/Conf" privFilter="*.objs.com"
pubFilter="*.edu|*.gov" other="/Sorry.html"
servicedata="http://www.objs.com/service/router/initdata.xml"
servicedatatype="XML"/>
</Service>
</ServiceSet>
<ServiceSet phase="AFTER" event="GET">
<Service
servicename="Internet Weather Service"
serviceid ="com.objs.ia.Weather.weather"
servicetype="JAVA"
genericServiceType=""
serviceInterfaceType="BRAServiceObject"
hasInterface="false"
doInit="false"
serviceOrder="1"
>
<Params mdr="http://www.objs.com/weather/MDR:8017"
stats="ALL"/>
</Service>
</ServiceSet>
</IASpecification>
Implementation Optimization
Service specifications are used to dynamically assemble services together
to augment the behavior of an application. However, the specifications
are also used to dynamically assemble the components of the IA as well
(part of the metadata stored in the specifications aids in assembling the
IA). But, if the components will always come together in the same fashion
then an optimization would be to keep those components assembled and waiting
for the next invocation. This optimization has been at least partially
implemented.
© Copyright 1997, 1998 Object Services and Consulting,
Inc. Permission is granted to copy this document provided this copyright
statement is retained in all copies. Disclaimer: OBJS does not warrant
the accuracy or completeness of the information in this survey.
Last revised: September 15, 1998. Send comments
to Paul Pazandak.